 Java8新特性
Java8新特性
# 1. 概述
Java8 相对于以前的版本作出了很大的改进。在运行效率上提高了许多,Java对底层进行了优化,程序执行速度更快;代码更加简洁,新增了许多特性。
- lambda表达式
@FunctionalInterface函数式接口- 接口默认方法
- Stream API 函数式操作
- Optional工具解决NPE问题
- 新的日期时间API
- 支持重复的注解
@Repeatable - JVM底层使用元空间(Metaspace)替换永久代(PermGen space)
- 支持数组并行排序
- 改进类型推断
更多特性:https://www.oracle.com/java/technologies/javase/8-whats-new.html (opens new window)
# 2. Lambda表达式
lambda表达式使用 -> 表示,可以理解为匿名函数,支持在方法中传递方法,如:
Consumer<Integer> con = (x) -> System.out.println("参数值为:" + x);
con.accept(90);
2
lambda 表达式 左:()参数列表,且不用指定参数类型,因为jvm会自动进行参数推断,右:具体执行的功能,-> 是箭头符号或叫lambda表达式。
lambda 表达式必须要函数式接口的支持,函数式接口:指接口中只有一个抽象方法的接口接
lambda表达式必须要函数式接口(只有一个抽象方法的接口)的支持口可以用 @FunctionalInterface 来检查。
# 3. 函数式接口
- 定义函数式接口
本质上
函数式接口也是一种接口,支持继承接口、定义默认方法、静态方法;继承接口除外,是只能有一个抽象的方法。
@FunctionalInterface
public interface Compute<T, R> {
public R getValue(T t1, T t2);
}
2
3
4
public static void main(String[] args) {
Consumer<Integer> con = (x) -> System.out.println("参数值为:" + x);
con.accept(2);
// 指定传递的参数,函数中添加表达式既往成计算
Long opr = opr(1l, 2l, (x, y) -> (x + y));
System.out.println(opr);
}
private static Long opr(Long t1, Long t2, Compute<Long, Long> compute) {
return compute.getValue(t1, t2);
}
2
3
4
5
6
7
8
9
10
11
12
13
- Java中提供的核心函数式接口
| 接口 | 参数 | 返回类型 | 说明 |
|---|---|---|---|
| Predicate<T> | T | boolean | 断言 |
| Consumer<T> | T | void | 消费消息,无返回值 |
| Function<T,R> | T | R | 消费消息,经过加工处理后,得到一个新的值 |
| Supplier<T> | 无 | T | 获取数据,充当工厂方法 |
| UnaryOperator<T> | T | T | 继承Function<T,R>,对单条消息加工处理,产生相同类型的消息 |
| BinaryOperator<T> | (T, T) | T | 对2个消息加工操作,产生一个相同类型的消息 |

/**
* java提供了很多函数式接口,但是主要核心接口有四个分别为Consumer、Supplier、Predicate、Function
*/
@Test
public void test8() {
// 有参数,无返回值
Consumer<String> consumer = (x) -> System.out.println("我消费了" + x);
consumer.accept("500美元");
}
@Test
public void test9() {
// 有返回值,无参数。
Supplier<String> s = () -> Integer.toBinaryString(126);
String toBinaryString = s.get();
System.out.println(toBinaryString);
}
@Test
public void test10() {
// 有参数,有返回值
Function<String, Integer> fun = (x) -> Integer.valueOf(x);
Integer apply = fun.apply("123");
System.out.println(apply);
}
@Test
public void test11() {
// 断言接口
Predicate<String> pre = (x) -> x.equals("Lee");
System.out.println(pre.test("lee"));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 4. 方法引用和构造器引用
- 对象::方法名称 必须先创建对象,这里System.out创建了一个对象
// 有参数,无返回值
Consumer<String> consumer = (x) -> System.out.println("我消费了" + x);
consumer.accept("500美元");
PrintStream print= System.out;
Consumer<String> consumer2 = print::println;
consumer2.accept("ClassName::staticFuncationName");
2
3
4
5
6
- 类::静态方法名称
// 有参数,有返回值
Function<String, Integer> fun = (x) -> Integer.valueOf(x);
Integer apply = fun.apply("123");
System.out.println(apply);
Function<String, Integer> fun2 = Integer::valueOf;
System.out.println(fun2.apply("200"));
2
3
4
5
6
- 类::方法名称 前提:必须是第一个参数是调用者,第二参数是被调用作为方法的参数
@Test
public void test11() {
// 断言接口
BiPredicate<String, String> pre = (x, y) -> x.equals(y);
System.out.println("未简化的:"+pre.test("lee", "lee"));
BiPredicate<String, String> pre2 = String::equals;
System.out.println("简化:"+pre2.test("Lee", "Tom"));
}
2
3
4
5
6
7
8
9
- 类名::new 具体调用那个构造方法,根据函数式接口中的方法参数有关
- 数组类型::new
// 构造方法的引用ClassName::new
Function<String, Employee> e = (str) -> new Employee(str);
Employee employee = e.apply("李强");
System.out.println(employee);
Function<String, Employee> e2 = Employee::new;
System.out.println(e2.apply("Wang xiao er"));
// 数组的引用 Type[]::new
Function<Integer, String[]> s = (n) -> new String[n];
String[] apply = s.apply(22);
Function<Integer, String[]> s2 = String[]::new;
String[] apply2 = s2.apply(23);
2
3
4
5
6
7
8
9
10
11
12
13
# 5. Stream API
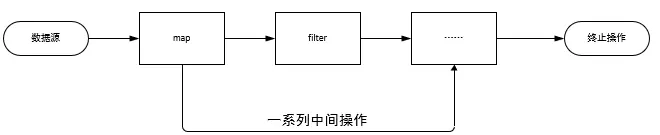
# 5.1. Stream 三大步骤
- 创建Stream
一个数据源(如:集合、数组),获取一个流
- 中间操作
一个中间操作,形成一条流的流水线
- 终止操作
一个中间操作,执行流水线,并能生成结果


# 5.2. Stream流的创建方式
//default Stream<E> stream() : 返回一个顺序流
//default Stream<E> parallelStream() : 返回一个并行流
//由给定的值创建流
Stream<String> of = Stream.of("abcd")
//通过Stream.iterate和Stream.generate创建无限流
Stream<Integer> generate = Stream.generate(() -> 2);
Stream<Integer> iterate = Stream.iterate(0, (x) -> x + 2)
//通过Arrays创建流
Arrays.Stream();
//通过list集合创建流
List<Stream> l = new ArrayList<>(); l.stream();
2
3
4
5
6
7
8
9
10
11
12
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”
# 5.3. 筛选
| 方法 | 说明 |
|---|---|
| filter(Predicate p) | 接收 Lambda ,从流中排除某些元素 |
| distinct() | 通过流所生成元素的 hashCode() 和 equals() 去除重复元素 |
| limit(long maxSize) | 获取指定 maxSize 个数元素 |
| skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 |
public void test1() {
List<Employee> emps = new ArrayList<Employee>();
emps.add(new Employee("James", 32));
emps.add(new Employee("Simith", 22));
emps.add(new Employee("Curay", 20));
emps.add(new Employee("TT", 23));
emps.add(new Employee("Boor", 12));
emps.add(new Employee("Boor", 12));
emps.add(new Employee("Boor", 12));
emps.add(new Employee("Boor", 12));
// 获取Stream流,可以使用Arrays工具类获取Stream流,中间操作后不做任何处理,除非发起终止操作。
Stream<Employee> stream = emps.stream();
// filter进行过滤处理操作,forEache迭代打印输出值,limit是截断流,截取给定数量的数据。
// skip顾名思义,跳过给定数量的数据。
stream.filter((x) -> x.getAge() > 20).limit(3).skip(1).forEach(System.out::println);
//打印输出年龄大于20的数据中的前三条数据,并跳过第一条数据。
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 5.4. 映射
| 方法 | 说明 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素 |
| flatMap (Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
| mapTolnt(TolntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream |
@Test
public void test2() {
//aa是个集合List<String> aa = Arrays.asList("aaa", "bbb", "ccc");
// map接受一个函数作为参数,并会应用到每一个集合中所有的元素,然后产生新的元素。
aa.stream().map((x) -> x.toUpperCase()).forEach(System.out::print);
}
@Test
public void test3() {
// map接受一个函数作为参数,并会应用到每一个集合中所有的元素,然后产生新的元素。
// aa.stream().map((x)->Java8Stream.toUpperCase(x)).forEach(System.out::print);
aa.stream().map(Java8Stream::toUpperCase).forEach((x) -> {
x.forEach(System.out::println);
});
// flatMap 同样接受一个函数作为参数,并将流中的一个值转换为一个新的流,然后合成一个流
aa.stream().flatMap(Java8Stream::toUpperCase).forEach(System.out::print);
}
public static Stream<Character> toUpperCase(String str) {
List<Character> c = new ArrayList<>();
for (Character v : str.toCharArray()) {
c.add(v.toUpperCase(v));
}
return c.stream();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 5.5. 归约
| 方法 | 说明 |
|---|---|
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional<T> |
List<Integer> caseUser = new ArrayList<CaseUser>() {{
add(new CaseUser("Tom", 22));
add(new CaseUser("Jack", 30));
add(new CaseUser("uRick", 26));
}}.stream()
.map(CaseUser::getAge)
.filter(a -> a >= 25)
.collect(Collectors.toList());
System.err.println(caseUser);
//依赖初始值countAge1
int countAge1 = 0;
for (int i = 0; i < caseUser.size(); i++) {
countAge1 += caseUser.get(i);
}
//通过reduce非常容易实现,依赖前一个数据值做归约计算
Integer countAge = caseUser.stream().reduce(Integer::sum).get();
System.err.println(countAge);
System.err.println(countAge1);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 5.6. 排序
// 排序
System.out.println("=============Sorted==================");
Stream<Employee> stream2 = emps.stream();
//根据Comparator比较器来排序,默认不带比较器情况下,按照类实现的Comparable来排序,也就是自然排序。
stream2.sorted((x, y) -> Integer.compare(x.getAge(), y.getAge())).forEach(System.out::println);
2
3
4
5
# 5.7. Stream的终止操作方法有哪些
| 方法 | 说明 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
@Test
public void test4() {
List<Employee> emps = new ArrayList<Employee>();
emps.add(new Employee("James", 32));
emps.add(new Employee("Simith", 22));
emps.add(new Employee("Curay", 20));
emps.add(new Employee("TT", 23));
emps.add(new Employee("Boor", 12));
emps.add(new Employee("Boor", 12));
emps.add(new Employee("Boor", 12));
emps.add(new Employee("Boor", 12));
boolean allMatch = emps.stream().allMatch((x) -> x.getAge() > 20);
System.out.println(allMatch);
boolean anyMatch = emps.stream().anyMatch((x) -> x.getAge() > 20);
System.out.println(anyMatch);
boolean noneMatch = emps.stream().noneMatch((x) -> x.getAge() < 0);
System.out.println(noneMatch);
Optional<Employee> findFirst = emps.stream().findFirst();
System.out.println(findFirst);
System.out.println("=============并行流,findAny流中取出任意一个元素。当前流=========");
Optional<Employee> findAny = emps.parallelStream().findAny();
System.out.println(findAny);
/**
* false
true
true
Optional[Employee [name=James, age=32]]
=============并行流,findAny流中取出任意一个元素。当前流======
Optional[Employee [name=Boor, age=12]]
* /
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| 方法 | 说明 |
|---|---|
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 遍历集合,集合框架内部已经实现迭代方法 |
# 5.8. 收集
Collect(Collector c) 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法,Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到 List、 Set、 Map)。但是 Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,常见方法如下:
List<CaseUser> caseUserList = new ArrayList<CaseUser>() {{
add(new CaseUser("Tom", 22));
add(new CaseUser("Jack", 30));
add(new CaseUser("uRick", 26));
add(new CaseUser("Zhuzu", 26));
}};
//获取年龄List集合
List<Integer> collect = caseUserList.stream().map(CaseUser::getAge).collect(toList());
//通过","链接用户名
String joinUserName = caseUserList.stream().map(CaseUser::getName).collect(joining(","));
//根据年龄分组,然后将分组得到User,取出用户名
Map<Integer, Set<String>> ageGroupByName = caseUserList.stream().collect(groupingBy(CaseUser::getAge, mapping(CaseUser::getName, toSet())));
//按年龄分组,并将User分组转换为只读List
Map<String, List<CaseUser>> listMap = caseUserList.stream().collect(groupingBy(CaseUser::getName, collectingAndThen(toList(), Collections::unmodifiableList)));
//获得年龄最小的User
Optional<CaseUser> min = caseUserList.stream().min(Comparator.comparing(CaseUser::getAge));
//Integer collect1 = caseUserList.stream().collect(summingInt(CaseUser::getAge));
//统计count,sum,min,max,avg
IntSummaryStatistics collect1 = caseUserList.stream().collect(summarizingInt(CaseUser::getAge));
//以年龄是否大于22作为分区,获取分区数据
Map<Boolean, List<CaseUser>> partitionByage = caseUserList.stream().collect(partitioningBy(u -> u.getAge() > 22, toList()));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 5.9. 并行流
在这个数据爆发式的年代,多核处理器已随处可见,压榨多核性能,在Java8中Stream API支持并行流处理任务,他底层依赖Fork/Join框架来处理;在StreamSupport工具类提供创建并行流的方式
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
2
3
4
5
6
在使用并行流时要注意,使用并行处理不一定比串行性能会更好。它受处理器、数据体量、数据结构影响较大。
- 数据大小: 数据足够大、 每个数据处理管道花费的时间足够多时, 并行化处理才有意义;
- 数据结构: 在Java8中并行处理数据是基于Fork/Join框架实现的,在集合数据结构中采用
Spliterator来拆分数据的,那么具备良好的拆分性能的集合,使用并行处理,性能会更好。如ArrayList、数组容易拆解,而HashSet、 TreeSet、LinkedList受限于结构,拆解性能较差;同时在处理数据时尽量使用无状态流,避免使用有状态流,像 sorted、 distinct 和 limit 等方法就是有状态的, map、filter 和 flatMap 等是无状态的。 - 处理器核数: 并行化本质就是利用处理器的多个核,单核也就没必要并行,并行化处理时,还要考虑能够使用几个核来提升性能;
- 单元处理开销: 只有在拆解的流中,处理单元任务耗时较长,采用并行处理效率才能更好;
- 拆箱装箱: 对于处理基本类型的流运算,尽量使用基本类型的流API,因为涉及拆箱装箱转换性能较差。
# 6. 接口中默认方法和静态方法
默认方法能够很好解决接口拓展问题,当接口需要拓展时不需要具体的实现类实现拓展,起着一个适配的功能。 默认方法需要default修饰,并且只有实现接口的类才能使用。 静态方法是可以被其他类共享
- 冲突解决原则
- 接口默认方法的“类优先” 原则若一个接口中定义了一个默认方法,而另外一个父类或接口中又定义了一个同名的方法时,选择父类中的方法。
- 如果一个父类提供了具体的实现,那么接口中具有相同名称和参数的默认方法会被忽略。
- 接口冲突时,如果一个父接口提供一个默认方法,而另一个接口也提供了一个具有相同名称和参数列表的方法(不管方法是否是默认方法), 那么必须覆盖该方法来解决冲突
- 接口中方法定义
public interface MyInterface {
int test();
default void demo(){
System.out.println("呵呵,我是Java8中默认的方法");
};
public static void wowo(){
System.out.println("我是接口中的静态方法哟。。。");
}
}
2
3
4
5
6
7
8
9
# 7. 新的时间API
LocalDate、 LocalTime、 LocalDateTime 类 的实例是不可变的对象,分别表示使用 ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息。也不包含与时区相关的信息。
注: ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法
- Instant: 用于“时间戳”的运算。它是以Unix元年(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的描述进行运算
- Duration: 用于计算两个“时间”间隔
- Period: 用于计算两个“日期”间隔
- 时区处理
- Java8 中加入了对时区的支持,带时区的时间为分别为:
- ZonedDate、 ZonedTime、 ZonedDateTime 其中每个时区都对应着 ID,地区ID都为 “{区域}/{城市}”的格式例如 : Asia/Shanghai 等
- ZoneId: 该类中包含了所有的时区信息
- getAvailableZoneIds() : 可以获取所有时区时区信息
- of(id): 用指定的时区信息获取 ZoneId 对象
- 时间格式化 java.time.format.DateTimeFormatter 类:该类提供了三种格式化方法:预定义的标准格式、语言环境相关的格式、自定义的格式
- 时间矫正器
- TemporalAdjuster: 时间校正器。有时我们可能需要获取例如:将日期调整到“下个周日”等操作。
- TemporalAdjusters : 该类通过静态方法提供了大量的常用 TemporalAdjuster 的实现。
# 8. Optional
Optional
<T>类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用null表示一个值不存在,现在Optional可以更好的表达这个概念。并且可以避免空指针异常。
| 方法 | 作用 |
|---|---|
| Optional(T value) | 创建Optional,value不可为空 |
| empty() | 创建一个空的Optional实例 |
| of(T value) | 创建一个Optional实例 |
| ofNullable(T value) | 若value不为null,创建Optional实例,否则创建空实例 |
| get() | 获取Optional中包装的数据,若为null,抛出异常NoSuchElementException |
| isPresent() | 判断是否包含值 |
| orElse(T other) | 如果调用对象包含值,返回该值,否则返回other |
| orElseGet(Supplie supplier) | 如果调用对象包含值,返回该值,否则返回supplier获取的值 |
| map(Function mapper) | 如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty() |
| flatMap(Function mapper) | 与map类似,要求返回值必须是0ptional |
| filter(Predicate predicate) | 过滤数据,若为空则返回当前对账,否则返回满足条件的 |
# 9. 参考
- 《Java 8函数式编程》 [英] Richard Warburton 著 王群锋 译