 深入理解Lambda
深入理解Lambda
Lambda作为JDK8引入的新特性,算是一个颠覆性特性,极大的改变Java原有的编码方式,大大减少了过多的样板代码;Lambda的引入让编码更加简洁易读,同时提高了编码效率。其实它也没那么神秘,底层封装实现其实就是基于匿名内部类来完成的,只不过转换、编译已经由JDK来完成大量的工作。
为了能够在编码中游刃有余,合理运用Lambda能够提高工作效率,改善代码性能,深入了解它的内部实现机制实属必要。而且通过洞悉内部细节,能够从中学到很多巧妙的技巧和实现原理。
# 1. 流水线
List<Integer> caseUser = new ArrayList<CaseUser>() {{
add(new CaseUser("Tom", 22));
add(new CaseUser("Jack", 30));
add(new CaseUser("uRick", 26));
}}.stream()
.map(CaseUser::getAge)
.filter(a -> a >= 25)
.limit(2)
.collect(Collectors.toList());
//上述操作可分解为5个过程,每一个过程都产生一个Stream对象,形成一个Stream对象流水线
Stream<CaseUser> stream = caseUser.stream();
Stream<Integer> mapStream = stream.map(CaseUser::getAge);
Stream<Integer> filterStream = mapStream.filter(a -> a >= 25);
Stream<Integer> limitStream = filterStream.limit(2);
List<Integer> result = limitStream.collect(Collectors.toList());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
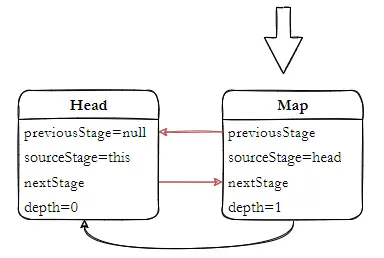
如图可以看出每个 Stream 都是一个 ReferencePipeline 类型对象,也就是这条流水线操作上的管道, 接下来深入探索流水线上每个 Stream 是如何实现的?怎么工作的?
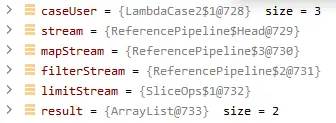
Stream 是通过 AbstractPipeline 建立的一条流水线管道,基于不同的子类实现不同的流水线上操作通路,编码创建的 Stream 对象就是流水线上的工位,流水线的运行则是在构建完成之后触发的,这里是在 collect(Collectors.toList()) 触发的惰性求值。那么 AbstractPipeline 是如何构建的流水线管道的呢?
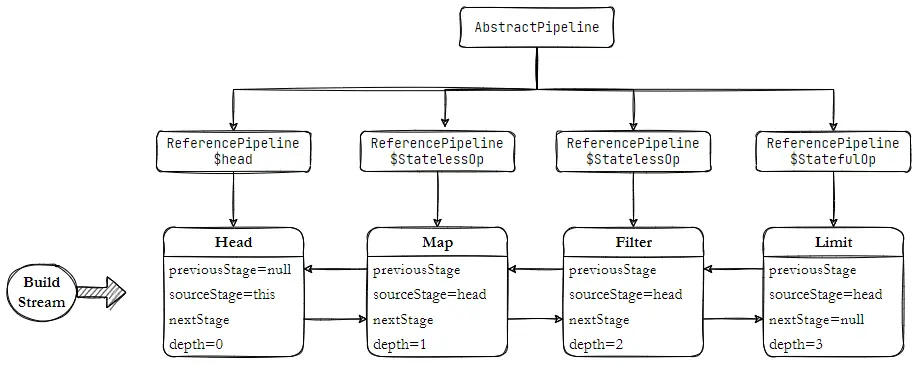
如上,一条完整流水线的内部结构,本质上就是通过 AbstractPipeline 来完成串联形成条流水管道;对于引用类型实例,则使用 ReferencePipeline 来完成构建,内部定义 Stream API方法实现。在流水线上的操作分为 有状态操作 、无状态操作;在并发流使用过程中,尽量避免使用 有状态操作,因为它涉及到多个任务的分割,操作结果的归并处理,性能上有所损耗。
# 1.1. 构建流水线
Stream 的构建依赖 Pipeline Head,每条流水线都需要先构建 Header,对于头的构建依赖 StreamSupport 工具类,StreamSupport 提供 Stream 静态构建方法,它需要提供 Spliterator 参数。而 Spliterator 是一个遍历和分隔元素的对象,在集合、数组、IO操作中都有对应的实现,下文再对它单独分析。

- 创建Header
//1.Collection create spliterator
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
//2.Collection create stream
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
//3.StreamSupport create head
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator, StreamOpFlag.fromCharacteristics(spliterator), parallel);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
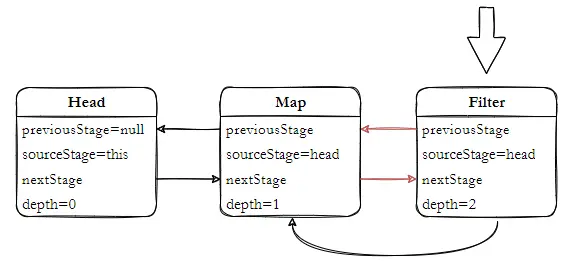
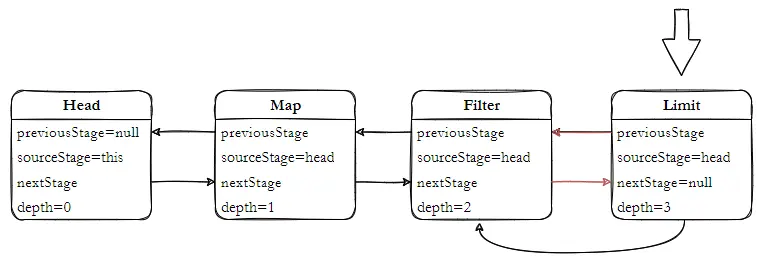
跟踪源码,在集合框架中,Collection 接口提供默认的实现方法,最后通过 StreamSupport 构建头,创建 Head 为 ReferencePipeline 内部类,Head 对象最终指向 AbstractPipeline;ReferencePipeline 内部定义3个内部类,分别对应不同的操作,内部关系结构如下。
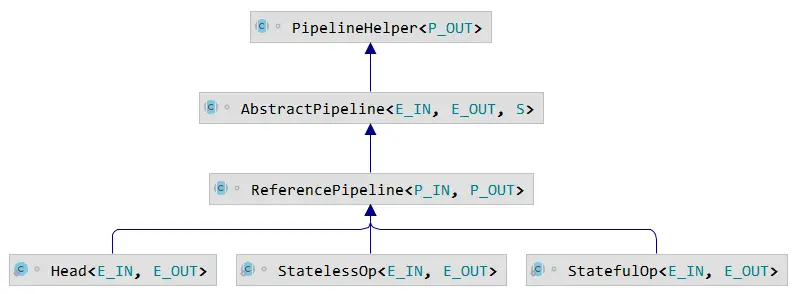
整个流 Pipeline 在 AbstractPipeline 定义, ReferencePipeline 只是针对引用类型的一种实现,对原生的基本类型Int、Long、Double 都有对应实现;Head 是 Pipeline 中的一个特殊节点,没有提供 opIsStateful、opWrapSink 方法的实现。
接下来看 AbstractPipeline 中重点细节。
private final AbstractPipeline sourceStage;//head
private final AbstractPipeline previousStage;//上游Pipeline
private final AbstractPipeline nextStage;//下游pipeline
private int depth;//Pipeline 深度,用于后续做回溯遍历
private boolean linkedOrConsumed;//标记当前Pipeline 是否链接或者被消费过
private boolean sourceAnyStateful;//标记head 是否为有状态的流水线
private boolean parallel;//标记并行流
/**
* 通过 Supplier 提供的 Spliterator 构建 Head
*/
AbstractPipeline(Supplier<? extends Spliterator<?>> source, int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSupplier = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
/**
* 通过 Spliterator 构建 Head
*/
AbstractPipeline(Spliterator<?> source, int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
/**
* 根据上游 Pipeline 构建 流水线上的操作
* @param previousStage 上游Pipeline
* @param opFlags 操作标识
*/
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
//若已经被链接或消费,不允许创建操作
if (previousStage.linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;//标记链接
previousStage.nextStage = this;//与上游 Piepline 链接
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;// Pipeline Head
//是否有状态的操作,只要在流水线上,存在一个操作是有状态的,则标记 sourceStage 为有状态的操作
if (opIsStateful()) sourceStage.sourceAnyStateful = true;
//深度+1
this.depth = previousStage.depth + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
- 创建Map
创建一个 Map 是一个无状态的 StatelessOp 操作,P_OUT 为 ,mapper 接收的参数,这里是 CaseUser 实例,R 为返回的流数据;StatelessOp 是一个无状态的操作,它继承 ReferencePipeline, 且仅实现了 opIsStateful 方法,用于标识一个无状态的操作,通过调用父 AbstractPipeline#AbstractPipeline(java.util.stream.AbstractPipeline<?,E_IN,?>, int) 方法来构建操作节点,入参中this 为上一个节点 Stream 对象,在这里是 head,也就是 caseUser.stream() 创建的 Stream<CaseUser>,通过构造函数巧妙与头连接起来。
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
//构建回溯链Sink,用于后续求值的时候使用
//Sink 中实现的方法 accept 其实这里就是触发惰性求值时,具体的数据处理逻辑
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
//接收CaseUser,将数据传递给下游downstream sink
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 创建Filter
Filter 的构建过程同 Map 是一样的流程,区别就在 opWrapSink 方法提供的 Sink 存在区别。
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
//满足过滤条件的数据,才能传递给下游,age > 25 时满足条件
if (predicate.test(u)) downstream.accept(u);
}
};
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 创建Limit
Limit 构建相对于 Map 和 Filter 有一定的区别,它通过 SliceOps 工厂类 makeRef 方法创建一个有状态的 ReferencePipeline.StatefulOp 。makeRef 方法合并了流操作的 limit 和 skip 方法,提供2种策略的实现。
public final Stream<P_OUT> limit(long maxSize) {
if (maxSize < 0) throw new IllegalArgumentException(Long.toString(maxSize));
return SliceOps.makeRef(this, 0, maxSize);
}
public final Stream<P_OUT> skip(long n) {
if (n < 0) throw new IllegalArgumentException(Long.toString(n));
if (n == 0) return this;
else return SliceOps.makeRef(this, n, -1);
}
2
3
4
5
6
7
8
9
10
在创建 Sink.ChainedReference 对象时,提供了 limit、skip 的实现;当构建 skip 操作时,其实也包含 limit 操作,只不过这个值是 Long.MAX_VALUE,没有过多的复杂逻辑,非常简洁。
//ReferencePipeline.StatefulOp#opWrapSink
Sink<T> opWrapSink(int flags, Sink<T> sink) {
return new Sink.ChainedReference<T, T>(sink) {
long n = skip;//skip 元素个数
//无论是limit,还是skip操作,m都存在值
long m = limit >= 0 ? limit : Long.MAX_VALUE;
@Override
public void begin(long size) {
downstream.begin(calcSize(size, skip, m));
}
@Override
public void accept(T t) {
if (n == 0) {//若是skip 则递减为0 后执行 limit 操作
if (m > 0) {//limit操作
m--;
downstream.accept(t);
}
}
else { //skip操作,n递减为0时,
n--;
}
}
@Override
public boolean cancellationRequested() {
return m == 0 || downstream.cancellationRequested();
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 1.2. 构建Sink
Sink 是 Consumer 接口的拓展,定义了数据处理的规范流程,它主要处理 Stream Pipeline 上的数据,并且有严格处理流程;Sink 定义了2种状态:初始状态、激活状态,且分别通过 begin() 和 end()来完成。当 Sink 需要接受数据之前,需要通过 begin() 方法转换为激活状态,只有处于激活状态的 Sink 才能通过 accept() 接受数据,数据处理完成后,必须通过 end() 重置状态。
当然,Sink 可以选择是否接受数据,可以通过 cancellationRequested() 来传递通知。
interface Sink<T> extends Consumer<T> {
default void begin(long size) {}
default void end() {}
default boolean cancellationRequested() {
return false;
}
}
2
3
4
5
6
7
Sink 接口中已经定义了基础的实现,有一个特别注意的实现 ChainedReference , 在流水线触发工作时,用来构建一个流中间操作 Sink 链式结构,具体的构建过程,下一节中介绍。

# 1.3. 运行流水线
通过 limitStream.collect(Collectors.toList()) 触发流水线运行;在执行之前需要通过构建 TerminalOp 操作,紧接着通过流水线上定义的操作构建回溯执行 Sink, 最后完成流水线作业,通过 Collector 收集结果。
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
if (isParallel() //并行处理,且collector是支持并发、数据是无序的
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else { //通用处理
container = evaluate(ReduceOps.makeRef(collector));
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 构建TerminalOp
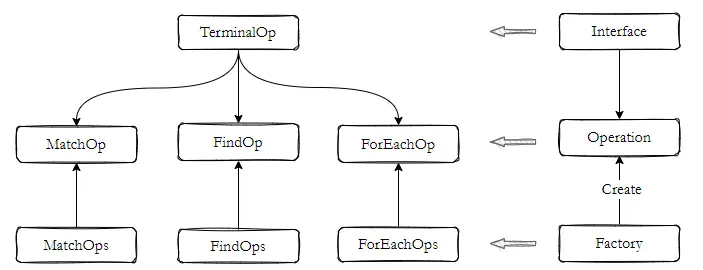
使用 ReduceOps 工厂类方法 ReduceOps.makeRef(collector) 构建一个 TerminalOp 操作 ReducingSink,主要目的是用于汇聚、收纳流水线处理的数据。
ReduceOp 是 TerminalOp 接口的一种具体实现,常见的实现有 ForEachOp、FindOp、MatchOp。
public static <T, I> TerminalOp<T, I> makeRef(Collector<? super T, I, ?> collector) {
Supplier<I> supplier = Objects.requireNonNull(collector).supplier();
BiConsumer<I, ? super T> accumulator = collector.accumulator();
BinaryOperator<I> combiner = collector.combiner();
//收集整合通过 Stream Pipeline 得到的数据
class ReducingSink extends Box<I> implements AccumulatingSink<T, I, ReducingSink> {
@Override
public void begin(long size) {
state = supplier.get();
}
@Override
public void accept(T t) {
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED) ? StreamOpFlag.NOT_ORDERED : 0;
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
evaluate 方法非常简单,根据流的特征,分发调用不同的方法,并行流调用 evaluateParallel 方法,串行流调用 evaluateSequential。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
2
3
4
5
6
7
8
- 包装Sink
根据文章开头的示例,会调用 terminalOp.evaluateSequential 方法,实现非常简单,通过 makeSink() 抽象方法构建 ReducingSink,也就是 ReduceOps.makeRef(collector) 创建的。
然后由回到 PipelineHelper#wrapAndCopyInto 处理,其实 AbstractPipeline 就是 PipelineHelper 实现,经历流水线处理后返回 ReducingSink,再调用 get() 获取最终的结果;
// ReduceOp 实现 evaluateSequential
public <P_IN> R evaluateSequential(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
// AbstractPipeline 实现wrapAndCopyInto
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);//构造Sink.ChainedReference,并执行 Sink 链
return sink;
}
2
3
4
5
6
7
8
9
10
继续探索 wrapSink 方法会发现,其实就是根据流水线上的操作定义创建一些列 Sink,然后维护成一个链结构。
// AbstractPipeline 实现wrapSink
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
//根据Pipeline深度depth,遍历opWrapSink 构建 Sink Chain
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
2
3
4
5
6
7
8
9
这里设计也非常巧妙,通过 opWrapSink 反向迭代 Pipeline 获得 Sink.ChainedReference 结构。
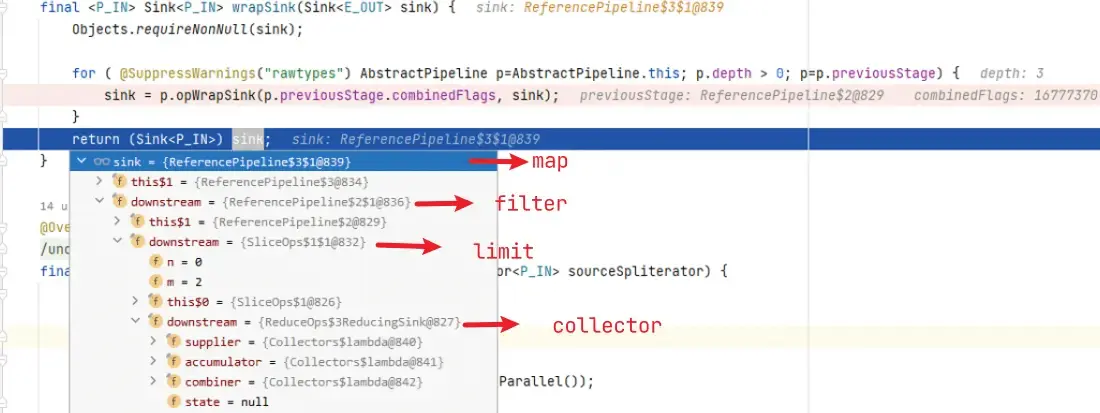
按照 ReferencePipeline 构建的 Pipeline 链深度 depth 反向迭代,构建一个 Sink.ChainedReference 结构的链,它仅有一个属性 downstream。
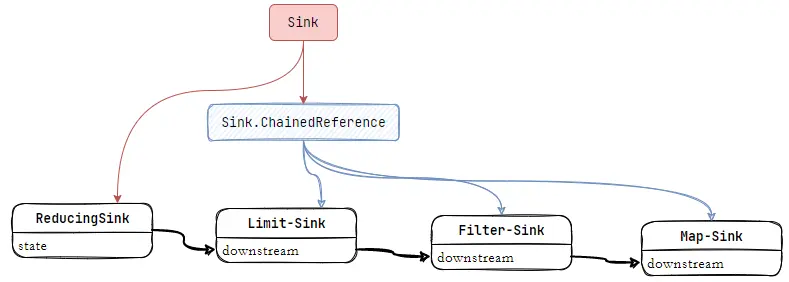
- 执行Sink Chain
Sink 接口继承 Consumer 接口,同时内部自定义多个默认方法 accept 方法用于接收数据;在触发 Stream 流水线时,同样通过 Pipeline 的 depth 迭代获取 head,然后把包装后的 Sink 链传递到数据源 Spliterator 实例中,数据源就是 ArrayList<CaseUser> 集合;Spliterator 是 Java8 之后新增的API,支持数据分割迭代,主要是为了适应并行流数据处理,便于 Fork/Join 拆解处理数据。
// AbstractPipeline 实现copyInto
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
//是否为短路操作,并行流中运用
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
// AbstractPipeline 实现copyIntoWithCancel
final <P_IN> void copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
AbstractPipeline p = AbstractPipeline.this;
//遍历得到 ReferencePipeline.Head
while (p.depth > 0) {
p = p.previousStage;
}
//启动stream
wrappedSink.begin(spliterator.getExactSizeIfKnown());
//将sink chain 传递给spliterator
p.forEachWithCancel(spliterator, wrappedSink);
//结束stream
wrappedSink.end();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
在执行 Sink 之前,需要遍历 Pipeline 得到 ReferencePipeline.Head,主要原因是在定义 Stream 操作时,在 Pipeline 链上可能出现其他类型,如IntStream、LongStream、DoubleStream,因为它们的 forEachWithCancel 方法实现是有区别的。
//ReferencePipeline 实现forEachWithCancel
final void forEachWithCancel(Spliterator<P_OUT> spliterator, Sink<P_OUT> sink) {
//传递Sink 给 spliterator 一次执行 Sink 链上的 downstream
do { } while (!sink.cancellationRequested() && spliterator.tryAdvance(sink));
}
2
3
4
5
Sink 执行前,通过 wrappedSink.begin(spliterator.getExactSizeIfKnown()) 通知每个 Sink 做好准备工作,Sink 执行时,将 Sink.ChainReference 传递 spliterator 遍历集合中的元素,执行流程如下:
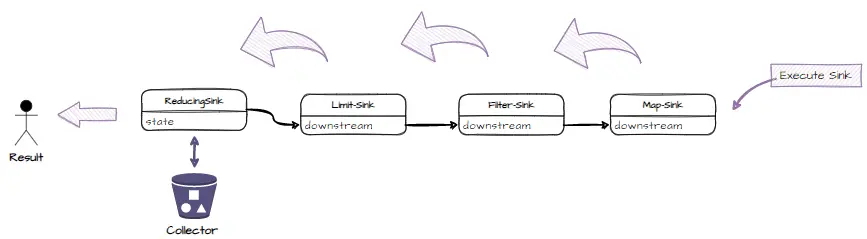
Sink 执行结束后,通过 wrappedSink.end() 方法通知每个 Sink 处理结束。
至此,整个 Stream 执行流程已经走完。当然 Stream 的操作方法还有许多,构建过程、实现方法大同小异,可以参考示例流程跟踪源码实现。
# 2. 并行流
启用并行流非常的简单,仅需要调用 parallelStream() 即可,其实就是设置一个并行标记,具体的处理逻辑与普通的流没有任何区别;区别在执行流时,使用 Fork/Join 任务框架结合集合的 Spliterator 策略来完成。
List<Integer> caseUser = new ArrayList<CaseUser>() {{
add(new CaseUser("Tom", 22));
add(new CaseUser("Jack", 30));
add(new CaseUser("uRick", 26));
}}.stream()
.map(CaseUser::getAge)
.filter(a -> a >= 25)
.limit(2)
.collect(Collectors.toList());
//上述操作可分解为5个过程,每一个过程都产生一个Stream对象,形成一个Stream对象流水线
//Stream<CaseUser> stream = caseUser.stream();
//Stream<CaseUser> stream = caseUser.stream().parallel();
Stream<CaseUser> stream = caseUser.parallelStream();
Stream<Integer> mapStream = stream.map(CaseUser::getAge);
Stream<Integer> filterStream = mapStream.filter(a -> a >= 25);
Stream<Integer> limitStream = filterStream.limit(2);
List<Integer> result = limitStream.collect(Collectors.toList());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
并行流的处理核心在于集合框架通过 Spliterator 来支持数据分割,以便于多任务并行处理;在本例中,并行处理数据从 collect(Collectors.toList()) 方法出现分支,改变流水线逻辑是 evaluate 方法。
//AbstractPipeline 方法 evaluate
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
2
3
4
5
6
7
8
9
对于并行流在执行 evaluateParallel 方法前,通过 sourceSpliterator(terminalOp.getOpFlags()) 方法解析流水线操作标识;如果是有状态的操作,会先遍历 Pipeline 链重写 spliterator 、操作的flag、以及 Pipeline 链的深度。
# 2.1. 重写SourceSpliterator
//AbstractPipeline 方法 sourceSpliterator
private Spliterator<?> sourceSpliterator(int terminalFlags) {
//得到数据源spliterator
Spliterator<?> spliterator = null;
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}else {
throw new IllegalStateException(MSG_CONSUMED);
}
//并行流,有状态的操作
if (isParallel() && sourceStage.sourceAnyStateful) {
//遍历Pipeline中的每一个有状态的操作,基于数据源spliterator创建一个新的spliterator适配器,并对每个操作流flag和Pipeline 深度进行调整。
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;u != e;u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {//有状态
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
//清除SHORT_CIRCUIT标识,在运行流水线是使用 spliterator.forEachRemaining 方法
//AbstractPipeline#copyInto 方法中有逻辑判断,因为重写spliterator,在该阶段已经处理了数据,该操作阶段已经有处理结果
//下一个操作阶段,只需要基于当前阶段产生的数据进行处理
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
//本例中Limit操作是有状态的,因此遍历pipeline时,执行Limit中重写的ReferencePipeline.StatefulOp#opEvaluateParallelLazy方法。
spliterator = p.opEvaluateParallelLazy(u, spliterator);
thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED) ? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED
: (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED;
}
p.depth = depth++;
p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags);
}
}
if (terminalFlags != 0) {
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
回到 ReferencePipeline#limit 方法定义,通过工厂方法 SliceOps.makeRef(this, 0, maxSize) 创建的 StatefulOp 对象实现中。
//SliceOps#java.util.stream.ReferencePipeline.StatefulOp#opEvaluateParallelLazy
<P_IN> Spliterator<T> opEvaluateParallelLazy(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
long size = helper.exactOutputSizeIfKnown(spliterator);
if (size > 0 && spliterator.hasCharacteristics(Spliterator.SUBSIZED)) {//SUBSIZED计算(通过分割器trySplit方法拆解的操作)
return new StreamSpliterators.SliceSpliterator.OfRef<>( helper.wrapSpliterator(spliterator), skip, calcSliceFence(skip, limit));
} else if (!StreamOpFlag.ORDERED.isKnown(helper.getStreamAndOpFlags())) {//无序的计算
return unorderedSkipLimitSpliterator( helper.wrapSpliterator(spliterator),skip, limit, size);
}else {
//构建Slice任务并执行,最后得到一个适配过后的spliterator
return new SliceTask<>(this, helper, spliterator, castingArray(), skip, limit).invoke().spliterator();
}
}
2
3
4
5
6
7
8
9
10
11
12
# 2.2. 构建SliceTask
SliceTask 是一个 ForkJoinTask 任务,它并行执行流水线上 limit 之前的操作,然后通过 SpinedBuffer 来缓存收集数据。SliceTask 任务结构如下:
在 AbstractShortCircuitTask 定义任务拆分流程,它重写了 AbstractTask#compute 方法,而具体的业务处理在 SliceTask#doLeaf 方法中。
//AbstractShortCircuitTask
public void compute() {
//本例spliterator为java.util.ArrayList.ArrayListSpliterator
Spliterator<P_IN> rs = spliterator, ls;
long sizeEstimate = rs.estimateSize();
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
AtomicReference<R> sr = sharedResult;
R result;
while ((result = sr.get()) == null) {//轮询拿到结果
if (task.taskCanceled()) {//需要返回空
result = task.getEmptyResult();
break;
}
//是否满足任务拆分最小粒度
if (sizeEstimate <= sizeThreshold || (ls = rs.trySplit()) == null) {
result = task.doLeaf();//执行SliceTask#doLeaf
break;
}
//构建主子任务
K leftChild, rightChild, taskToFork;
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
task.setPendingCount(1);
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
//任务完成合并数据
task.setLocalResult(result);
//执行SliceTask重写的onCompletion方法
task.tryComplete();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
将主任务拆分为多个子任务执行,在Java 8 API中依赖 Spliterator 工具,在集合框架都有具体的实现,如何拆分数据的逻辑,由 trySplit() 抽象方法定义;因此对任务处理数据的拆分是依赖于数据源的,采用哪一种策略,在你决定使用的数据结构时,就已经确定,如本例中使用 ArrayList 作为数据源,应当查看 ArrayList 中拆分车略实现。
//SliceTask#doLeaf
protected final Node<P_OUT> doLeaf() {
if (isRoot()) {//根任务
long sizeIfKnown = StreamOpFlag.SIZED.isPreserved(op.sourceOrOpFlags) ? op.exactOutputSizeIfKnown(spliterator) : -1;
final Node.Builder<P_OUT> nb = op.makeNodeBuilder(sizeIfKnown, generator);
Sink<P_OUT> opSink = op.opWrapSink(helper.getStreamAndOpFlags(), nb);
helper.copyIntoWithCancel(helper.wrapSink(opSink), spliterator);
// There is no need to truncate since the op performs the
// skipping and limiting of elements
return nb.build();
} else {//叶子任务
//这里就回到普通的处理逻辑,执行AbstractPipeline#wrapAndCopyInto
//helper.makeNodeBuilder(-1, generator)得到一个SpinedNodeBuilder,它实现 Sink 接口
//走到这就非常清晰了,这里处理与普通流没有任何区别
Node<P_OUT> node = helper.wrapAndCopyInto(helper.makeNodeBuilder(-1, generator), spliterator).build();
thisNodeSize = node.count();
completed = true;
spliterator = null;
return node;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
到此为止,通过 sourceSpliterator(int terminalFlags) 得到了一个适配后的 Spliterator 实例,它的实现是 SpinedBuffer 数据结构,缓存了 Limit (包括Limit操作)之前的流水线执行的处理结果;接下来还要通过 terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) 收集结果。
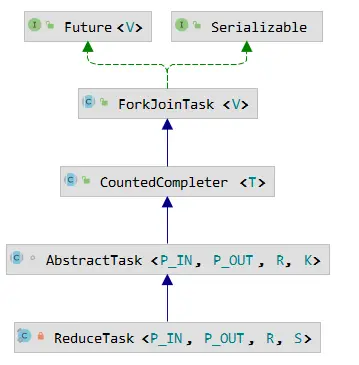
# 2.3. 构建ReduceTask
与 SliceTask 相同的处理逻辑,执行策略也没任何区别,不过这里处理的数据是依赖 SliceTask 处理的结果来完成;方法传入的 spliterator 实例时被重写过后的。
//java.util.stream.ReduceOps.ReduceOp#evaluateParallel
public <P_IN> R evaluateParallel(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
2
3
4
ReduceTask 也是一个 ForkJoinTask 任务,它内部结构如下,与 SliceTask 出自同源,只不过 SliceTask 继承 AbstractShortCircuitTask 并重写了 compute 方法。
通过断点调试,很容易看出 ReduceTask 任务处理的数据是被处理过的;任务的拆分流程由 AbstractTask 定义,ReduceTask 实现 AbstractTask 的模板方法 doLeaf() 。
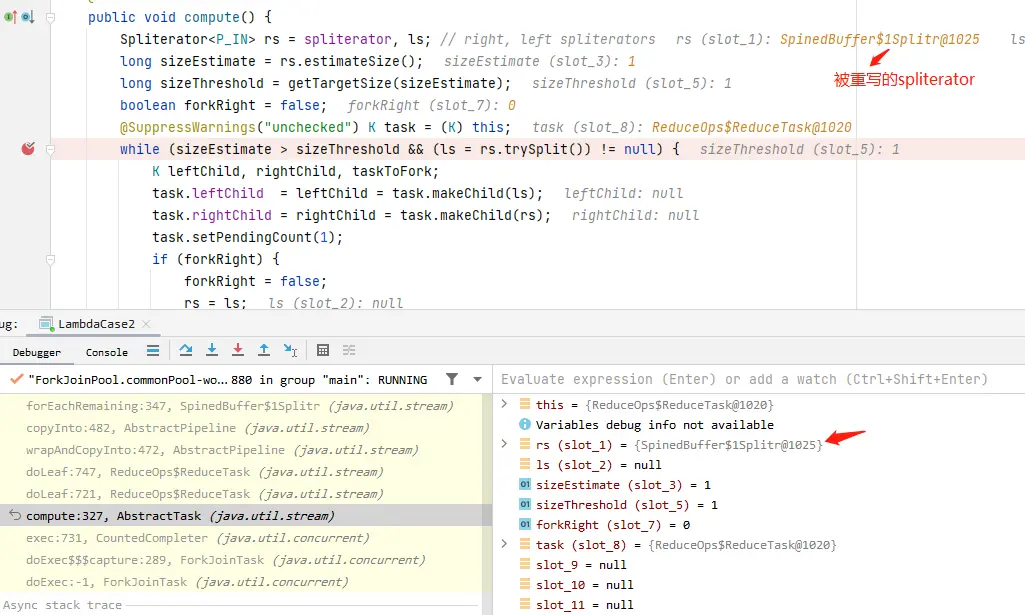
不过这里需要注意 wrapSink 和 copyInto 处理逻辑,因为 spliterator 被重写的同时 StreamAndOpFlags 、Pipeline depth 也是被处理过的。在 wrapSink 方法处理时 depth 为0,不会进入 for 循环遍历,而直接返回 ReduceOps$ReducingSink;copyInto 方法也不会进入 copyIntoWithCancel 方法,而是将 sink 传递给 spliterator。
需要注意的是 depth 为0,也就不会构建 Sink 是一个 Sink.ChainedReference 结构的链。
//1.ReduceTask#doLeaf
protected S doLeaf() {
return helper.wrapAndCopyInto(op.makeSink(), spliterator);
}
//2.AbstractPipeline#wrapAndCopyInto
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
//3.AbstractPipeline#wrapSink
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
//depth已被重写,不会遍历,直接返回sink(ReduceOps$ReducingSink)
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
//4.AbstractPipeline#copyInto
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
//不是SHORT_CIRCUIT,则直接执行spliterator,这里与2.1. 重写SourceSpliterator 处理有关
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
} else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 2.4. 关于fork/join任务
fork/join 任务框架是一套用于拆解大任务,合利利用CPU多核,便于并行计算提高数据处理运算效率。它在JDK7由 Doug Lea 大师开发,它采用 Work-Stealing (窃取)算法,把大任务分割为很多小任务,为了避免多线程竞争资源,导致压力过大,把每个任务放到不同的队列中维护;每个队列创建一个线程来处理数据,当其中一个队列数据处理完后,去其他线程队列窃取任务执行,这样一来就充分利用多线程并行处理任务。
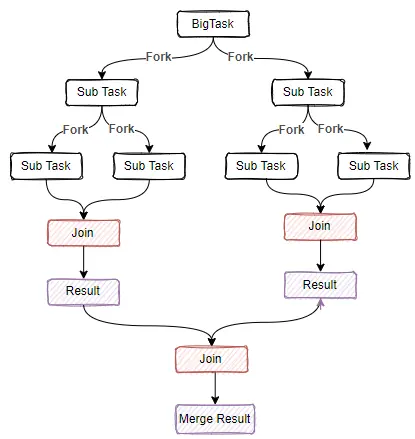
Join 方法阻塞当前线程等待获取到最终的结果,Fork 方法触发异步执行当前任务;fork/join框架任务的执行通过 ForkJoinPool 来执行 ForkJoinTask,当没有自定义 ForkJoinPool 时,使用 ForkJoinPool.commonPool() 公共线程池。
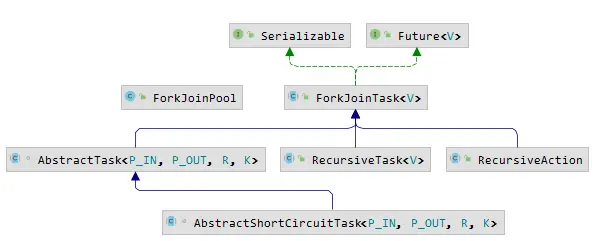
ForkJoinTask 主要几个实现:
- AbstractTask 提供 Stream 并行任务实现;
- RecursiveTask 提供有返回值的实现;
- RecursiveAction 提供无返回值的实现;
- AbstractShortCircuitTask 继承 AbstractTask ,提供 Stream 并行处理短路操作的任务。
只有大任务才适合拆解并行,小任务反而性能很差,在使用 ForkJoinTask 时,一定要做好性能测试。
一个简单的示例
public static void main(String[] args){
Integer sumTask = new AccumulatorTask(4).invoke();
}
/**
*
* 数字累加任务
*/
static class AccumulatorTask extends RecursiveTask<Integer> {
private final int end;
private final int start;
public AccumulatorTask(int end) {
this(0, end);
}
public AccumulatorTask(int start, int end) {
this.end = end;
this.start = start;
}
@Override
protected Integer compute() {
int sum = 0;
boolean result = end - start <= 2;//任务拆分阀值
if (result) {
for (int i = start; i <= end; i++) {
sum += i;//累加
}
} else {
int middle = (end + start) / 2;
AccumulatorTask leftTask = new AccumulatorTask(start, middle);
AccumulatorTask rightTask = new AccumulatorTask(middle + 1, end);
// 触发子任务
ForkJoinTask<Integer> leftFork = leftTask.fork();
ForkJoinTask<Integer> rightFork = rightTask.fork();
//等待执行结果
Integer leftResult = leftFork.join();
Integer rightResult = rightFork.join();
//合并结果
sum = rightResult + leftResult;
}
return sum;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 3. 总结
Stream 作为 Java 8 一个非常不错新增特性,支持 Lambda 表达式,大大提高了编码效率,避免写太多样板代码,可读性更好,总之好处太多了。但是在不了解内部实现机制时,盲目使用相关API可能适得其反,效率提高了,性能反而下降,也就得不偿失了。
特别对于并行流的使用,使用不正确非常的耗费资源。
- 数据大小: 数据足够大、 每个数据处理操作耗时足够长时, 并行化处理才有意义;
- 数据结构: 并行处理数据使用 Fork/Join 框架实现的,数据源需要采用
Spliterator来拆分数据的,那么具备良好的拆分性能的数据源,使得并行处理性能更好。如ArrayList、数组容易拆解,而HashSet、 TreeSet、LinkedList受限于结构,拆解性能较差;同时在处理数据时尽量使用无状态流,避免使用有状态流,因为有状态的流操作需要在流水线上多次传递数据。
| 操作 | 方法 |
|---|---|
| 有状态 | skip()、concat()、distinct()、sorted()、takeWhile()、dropWhile() |
| 无状态 | filter()、map()、peek()、flatMap() |
- 处理器核数: 并行化本质就是利用 CPU 多个核,单核也就没必要并行,并行化处理时,还要考虑能够使用几个核来提升性能;
- 单元处理开销: 只有在拆解的流中,处理单元(流操作)任务耗时较长,采用并行处理效率才能更好;
- 拆箱装箱: 对于处理基本类型的流运算,尽量使用基本类型的流API,因为涉及拆箱装箱转换性能较差。
# 4. 参考
- Parallel streams in Java: Benchmarking and performance considerations (opens new window)
- 《Java并发编程的艺术》方腾飞,魏鹏,程晓明 著