 Linux命令集
Linux命令集
Linux 作为主流的应用服务器系统,掌握基础应用命令非常有必要;本文收录笔者工作中使用到的常用命令,以及一些使用技巧。
# 1. 命令集
在不清楚命令的功能,以及相关指令是可以使用帮助命令
- man:查看Linux下的帮助命令信息
- help:获得 shell 内置命令的帮助信息,可通过
help [command]查看指定命令信息 - history:查看已经执行过历史命令,也可以执行历史指令
history 显示所有的使用过的命令
history 10 显示10条命令
!命令行号 执行history 对应的命令
2
3
# 1.1. 系统操作
系统级别
0:关机
1:单用户【找回丢失密码】
2:多用户状态没有网络服务
3:多用户状态有网络服务
4:系统未使用保留
5:图形界面
6:系统启动
运行级别修改:/etc/inittab 运行级别切换:init [级别]
2
3
4
5
6
7
8
警告
root密码忘记,可计入系统单用户模式,重置root密码(只有在机房进入)
# 2. 现在重启
shutdown -r now
# 现在关机
shutdown -h now
# 1分钟关机
shutdown -h 1
# 关机
halt
# 重启
reboot
# 3. 内存中的数据写到磁盘上,做关机或重启之前,做这样一个操作,养成良好的习惯
sync
# 注销
logout
# 关机
poweroff
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 1.2. 用户管理
- 命令
# 2. 添加用户
useradd [可选项] 用户名
# 3. 创建用户指定用户家目录
useradd -d 用户家目录 用户名
# 4. 创建一个用户指定所属用户组
useradd -g 用户组名 用户名
# 5. -g:加入主要组、-G:加入次要组
useradd –g sales jack –G company,employees
# 6. 修改用户组
usermod -g 新用户组名 用户名
# 7. 修改密码
passwd 用户名
# 8. 删除用户保留加目录
userdel 用户名
# 9. 删除用户同时删除家目录(正常工作不要删除家目录)
userdel -r 用户名
# 10. 推出
exit
# 11. 查询用户信息,uid:用户id,gid:组id,groups:所属组(组名)
id 用户名
# 12. 我是谁 查看当前用户
who am i
# 13. 创建组
groupadd 组名
# 14. 删除组
groupdel 组名
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 相关文件
- /etc/passwd:用户配置信息
含义:用户:口令:用户标识:组标识:备注:家目录:shell
- /etc/group:组配置信息
含义:组名:口令:组标识:组内用户列表
- /etc/shadow:口令配置信息
含义:登录名:口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标识
# 1.3. 权限管理
- chown 修改文件所有者
chown 用户名 文件名
chown -R或——recursive 用户名 文件列表(文件列表空格隔开):递归处理,将指定目录下的所有文件及子目录一并处理;
chown -v或——version 用户名 文件列表 :显示指令执行过程;
2
3
4
- chgrp 修改文件所在的组
chgrp 组名 文件名列表(文件列表空格隔开)
chgrp -R或——recursive 组名 文件名列表:递归处理,将指令目录下的所有文件及子目录一并处理;
chgrp -v或——verbose 组名 文件名列表:显示指令执行过程;
2
3
- chomd 授权操作(目录或文件)
通过chmod 指令,可以修改文件或者目录的权限。
u:所有者
g:所有组
o:其他人
a:所有人(u、g、o 的总和)
+ 表示增加权限、
- 表示取消权限、
= 表示唯一设定权限
2
3
4
5
6
7
8
chmod u=rwx,g=rx,o=x 文件目录名 对目录授权
chmod ugo+r file1.txt 给文件file1添加可读权限
chmod a+r file1.txt
chmod 755 /home/abc.txt 通过数字授权 r=4,w=2 x=1 rwx=4+2+1 rw=4+2 rx=4+1 wx=2+1
2
3
4
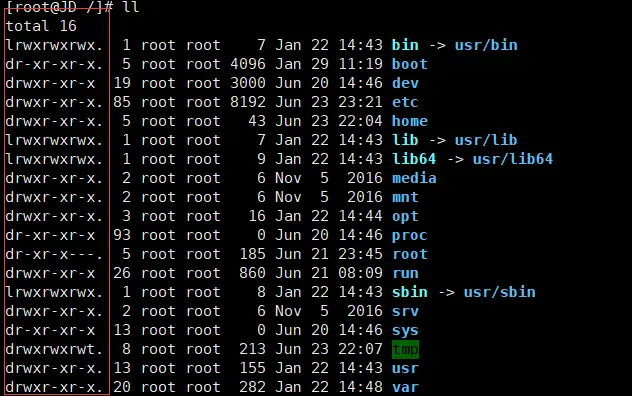
如上图权限点表示
dr-xr-xr-x
第 0 位确定文件类型(d[目录], -[普通文件] , l[软连接] , c[字符设备,如鼠标、键盘等等] , b[块文件、硬盘])
第 1-3 位确定所有者(该文件的所有者)拥有该文件的权限。---User
第 4-6 位确定所属组(同用户组的)拥有该文件的权限,---Group
第 7-9 位确定其他用户拥有该文件的权限 ---Other
2
3
4
5
权限详细说明
| 权限名称 | 名称 | 数字标识 | 说明 |
|---|---|---|---|
| r(read) | 读 | 4 | 可以读取,查看 |
| w(write) | 写 | 2 | 可以修改,但是不代表可以删除该文件,删除一个文件的前提条件是 对该文件所在的目录有写权限,才能删除该文件 |
| x(execute) | 可执行 | 1 | 可以被执行 |
# 1.4. 文件管理
pwd:显示当前目录绝对路径
ls:查看文件列表
ls -c: 以更改时间排序,显示文件和目录
ls -F: 在每个输出项后追加文件的类型标识符,
具体含义:“*”表示具有可执行权限的普通文件,“/”表示目录,“@”表示符号链接,“|”表示命令管道FIFO,“=”表示sockets套接字。当文件为普通文件时,不输出任何标识符;
ls -i或--inode: 显示文件和目录的inode编号
ls -I(i大写) 文件名称: 不显示指定的文件名称的文件列表
ls -l(小写的L): 显示列表详细信息
ls -m: 用","号区隔每个文件和目录的名称。
ls -n: 以用户识别码和群组识别码替代其名称。
ls -Q: 把文件和目录名称以""号标示起来
ls -r: 反向排序
ls -r: 显示文件和目录的大小,以区块为单位
ls -S: 用文件和目录的大小排序
ls -t: 用文件和目录的更改时间排序
ls -u: 以最后存取时间排序,显示文件和目录
ls -U: 列出文件不排序
ls -X: 以文件和目录的最后一个扩展名排序
ls --full-time: 列出完整的日期与时间
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- cd:切换目录
cd ~ 回到家目录
cd .. 上一级目录
cd !$ 把上个命令的参数作为cd参数使用。
cd ../.. 返回上两级目录
cd - 返回进入此目录之前所在的目录
2
3
4
5
- 文件目录操作
mkdir -p:创建多级目录
rmdir 删除的是空目录,如果目录下有内容时无法删除的
如果需要删除非空目录,需要使用 rm -rf 要删除的目录
touch :一是用于把已存在文件的时间标签更新为系统当前的时间(默认方式),它们的数据将原封不动地保留下来;二是用来创建新的空文件。
touch 文件名
touch -m 更新文件变更时间
cp: 拷贝文件到指定的目录
cp [选项] 源目录 目标目录
cp -r 源目录 目标目录 (递归复制整个目录)
cp -a/-dpR 复制文件(如果有符号链接相关文件也建立符号链接,同时保留文件和目录属性,并递归处理)
rm:remove 删除目录或文件
rm 文件或目录名1.1.4.7. > rm -r 递归删除文件夹
rm -f 强制删除不提示
rm -rf 强制递归删除不提示
rm -v 显示指令的详细执行过程。
rm -d 直接把欲删除的目录的硬连接数据删除成0,删除该目录(少用);
mv:移动文件或者文件重命名1.1.4.8. > mv 旧文件名 新文件名 (重命名)
mv 原目录 目标目录 (移动)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 查看文件
cat:查看文件,以只读的方式打开
cat [选项] 文件名
cat -n 显示行号
为了方便查看文件 一般cat 后面都会添加管道符‘|’如 cat v.txt | more
2
3
4
- more 指令是一个基于 VI 编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容
| 操作 | 功能说明 |
|---|---|
| 空白键(space) | 代表向下翻一页 |
| Enter | 代表向下翻一行 |
| q | 代表立刻离开 more,不再显示这文件内容 |
| Ctr + F | 向下滚动一屏 |
| Ctr + B | 返回滚动上一屏 |
| = | 输出当前行的行号 |
| :f | 输出文件名和当前行的行号 |
- less 指令用来分屏查看文件内容,它的功能与 more 指令类似,但是比 more 指令更加强大,支持各种显示终端。less 指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示
|操作| |功能说明|
|空白键(space) | |向下翻一页|
|[pagedown] | |代表向下翻一行|
|[pageup]|代表向上翻一行|
|q | |退出查看|
|/字符串 | |向下搜导[字符串]的功能,n: 向下查,N: 向上查|
|?字符串 | |向上搜寻[字符串]的功能,n: 向上查,N: 向下查|
2
3
4
5
6
7
- head 用于显示文件的开头部分内容,默认情况下 head 指令显示文件的前 10 行内容
head 文件
head -n 5 文件 显文件前5行内容,5可以是任意值
2
- tail 用于输出文件中尾部的内容,默认情况下 tail 指令显示文件的后 10 行内容
tail 文件
tail -n 5 文件
tail -f 文件/tailf 文件 实时追踪该文档的所有更新,工作经常使用
2
3
- 追加与重定向
\> 重定向,>> 追加
s -l > a.txt , 将 ls -l 的显示的内容覆盖写入到 a.txt 文件,如果该文件不存在,就创建该文
件。1.1.4.11. > ls -al >>文件 列表的内容追加到文件 aa.txt 的末尾,不会删除原有的
cat 文件 1 > 文件 2 (功能描述:将文件 1 的内容覆盖到文件 2)
2
3
4
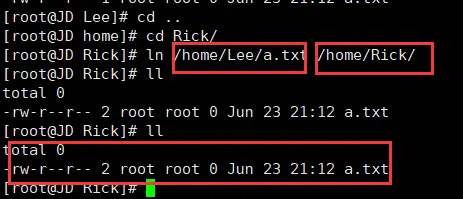
- 创建软连接
ln 源连接 软连接
软链接也叫符号链接,类似于 windows 里的快捷方式,主要存放了链接其他文件的路径 当我们使用 pwd 指令查看目录时,仍然看到的是软链接所在目录。
# 1.5. 时间日期
显示当前日期
date 显示当前日期
date '+%Y年%m月%d日 %H:%M:%S' 指定格式显示日期
date +%Y 显示当前年
date +%m 显示当前月
date +%d 显示当前日
date -s 字符串时间
2
3
4
5
6
7

查看日历
cal 显示当前日历
cal 2020 显示 2020 年日历
2
# 1.6. 搜索查找
- find 文件查找
指令将从指定目录向下递归地遍历其各个子目录,将满足条件的文件或者目录显示在终端。
find 目录 -size +20M 查找整个 linux 系统下大于 20m 的文件(+n 大于 -n 小于 n 等于)
find 目录 -name *.txt 查询指定目录下所有以.txt 文件结尾的文件
选项
-name<查询方式> 按照指定的文件名查找模式查找文件
-userc用户名> 查找属于指定用户名所有文件
-size<文件大小> 按照指定的文件大小查我文件
2
3
4
5
6
7
- locate 快速定位文件所在目录
locate 指令可以快速定位文件路径。它指令利用事先建立的系统中所有文件名称及路径的数据库快速定位文件;
Locate 指令无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确度,管理员必须定期更新 locate 数据库;
由于 locate 指令基于数据库进行查询,所以第一次运行前,必须使用 updatedb 指令创建 locate 数据库。
locate 目录 文件名
locate /etc/sh 搜索etc目录下所有以sh开头的文件
locate -i ~/m 搜索用户主目录下,所有以m开头的文件,并且忽略大小写
2
3
- grep 指令和管道符号
|查找
grep 过滤查找 , 管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理。1.1.5.3. > grep -i 忽略大小写
grep -n 显示行号
grep -v "match_pattern" file_name 显示除此之外的所有行
grep "match_pattern" file_name --color=auto 自动匹配颜色
grep -E "[1-9]+" 或 egrep "[1-9]+" 使用正则表达式
grep -o '呵呵' 只输出文件中匹配到的部分
grep "text" . -r -n . 表示当前目录
2
3
4
5
6
7
#只在目录中所有的.php和.html文件中递归搜索字符"main()"
grep "main()" . -r --include *.{php,html}
#在搜索结果中排除所有README文件1.1.6.2. grep "main()" . -r --exclude "README"
#在搜索结果中排除filelist文件列表里的文件
grep "main()" . -r --exclude-from filelist
2
3
4
5
-a 不要忽略二进制数据。
-A<显示列数 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。1.1.6.3. -c 计算符合范本样式的列数。
-C<显示列数或-<显示列数 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 1.7. 压缩和解压
- gzip/gunzip
当我们使用 gzip 对文件进行压缩后,不会保留原来的文件
gzip 用于压缩文件
gzip 压缩文件,只能将文件压缩为*.gz 文件
gunzip 用于解压的
gunzip 文件.gz 解压缩文件命令
2
3
4
- zip/unzip
zip 用于压缩文件, unzip 用于解压的,这个在项目打包发布非常实用
zip [选项] XXX.zip 将要压缩的内容(功能描述:压缩文件和目录的命令)
unzip [选项] XXX.zip (功能描述:解压缩文件)
zip -r 文件名 递归压缩,即压缩目录
uzip -d<目录> 指定解压后文件的存放目录
2
3
4
- tar指令
tar 指令 是打包指令,最后打包后的文件是 .tar.gz 的文件
tar [选项] XXX.tar.gz 打包的内容压缩后的文件格式.tar.gz
tar -cvf log.tar log2012.log 仅打包,不压缩!
tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩
tar -jcvf log.tar.bz2 log2012.log 打包后,以 bzip2 压缩
2
3
4
压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
查 询:tar -jtv -f filename.tar.bz2
解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
2
3
tar -zxvf /opt/soft/test/log.tar.gz 将tar包解压缩
tar -zxvf /opt/soft/test/log30.tar.gz log2013.log 只将tar内的部分文件解压出来
tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩
tar -zxvf /opt/a.tar.gz -C /opt/tools/java 将文件解压到指定位置
2
3
4
# 1.8. 任务调度
在 linux 主要通过 crontab 实现任务调度;
它用来提交和管理用户的需要周期性执行的任务,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
命令选项
-e:编辑该用户的计时器设置;
-l:列出该用户的计时器设置;
-r:删除该用户的计时器设置;
-u<用户名称>:指定要设定计时器的用户名称。
-e 定义任务调度 保存退出开始执行
2
3
4
5
相关文件说明
- /etc/cron.deny 该文件中所列用户不允许使用crontab命令
- /etc/cron.allow 该文件中所列用户允许使用crontab命令
- /var/spool/cron/ 所有用户crontab文件存放的目录,以用户名命名
- /etc/crontab:cron命令执行存放文件
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
#For details see man 4 crontabs
#Example of job definition:
#.---------------- minute (0 - 59)
#| .------------- hour (0 - 23)
#| | .---------- day of month (1 - 31)
#| | | .------- month (1 - 12) OR jan,feb,mar,apr ...
#| | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
#| | | | |
#* * * * * user-name command to be executed
#前4行是用来配置crond任务运行的环境变量
#第1行 SHELL 变量指定了系统要使用哪个shell,这里是bash
#第2行 PATH 变量指定了系统执行命令的路径
#第3行 MAILTO 变量指定了crond的任务执行信息将通过电子邮件发送给root用户,如果MAILTO变量的值为空,则表示不发送任务执行信息给用户
#第4行的 HOME 变量指定了在执行命令或者脚本时使用的主目录
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
cron 表达式说明
minute hour day month week command 顺序:分 时 日 月 周
- minute: 表示分钟,可以是从0到59之间的任何整数。
- hour:表示小时,可以是从0到23之间的任何整数。
- day:表示日期,可以是从1到31之间的任何整数。
- month:表示月份,可以是从1到12之间的任何整数。
- week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
- command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
- 星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
- 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
- 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
- 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
# 每1分钟执行一次command
* * * * * command
# 每小时的第3和第15分钟执行
3,15 * * * * command
# 在上午8点到11点的第3和第15分钟执行
3,15 8-11 * * * command
# 每隔两天的上午8点到11点的第3和第15分钟执行
3,15 8-11 */2 * * command
# 每个星期一的上午8点到11点的第3和第15分钟执行
3,15 8-11 * * 1 command
# 每晚的21:30重启smb
30 21 * * * /etc/init.d/smb restart
# 每月1、10、22日的4 : 45重启smb
45 4 1,10,22 * * /etc/init.d/smb restart
# 每周六、周日的1:10重启smb
10 1 * * 6,0 /etc/init.d/smb restart
# 每天18 : 00至23 : 00之间每隔30分钟重启smb
0,30 18-23 * * * /etc/init.d/smb restart
# 每星期六的晚上11:00 pm重启smb
0 23 * * 6 /etc/init.d/smb restart
# 每一小时重启smb
* */1 * * * /etc/init.d/smb restart
# 晚上11点到早上7点之间,每隔一小时重启smb
* 23-7/1 * * * /etc/init.d/smb restart
# 每月的4号与每周一到周三的11点重启smb
0 11 4 * mon-wed /etc/init.d/smb restart
# 一月一号的4点重启smb
0 4 1 jan * /etc/init.d/smb restart
# 每小时执行/etc/cron.hourly目录内的脚本
01 * * * * root run-parts /etc/cron.hourly
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 1.9. 磁盘管理
- 分区类型
- MRB(master boot record): 简称主引导记录或主引导扇区,它的运行机制存在于硬件的基础之上,数据存储在硬盘的第一个扇区
最多支持四个主分区
系统只能安装在主分区
扩展分区要占一个主分区
MBR 最大只支持 2TB, 但拥有最好的兼容性
- GTP:实用GUID分区表的磁盘称为GPT磁盘,与MBR相比,GPT提供了更加灵活的磁盘分区机制
支持无限多个主分区(但操作系统可能限制, 比如 windows 下最多 128 个分区)
最大支持 18EB 的大容量(1EB=1024 PB, 1PB=1024 TB )
windows7 64 位以后支持 gtp
- 关于Linux的分区
Linux 来说无论有几个分区, 分给哪一目录使用, 它归根结底就只有一个根目录, 一个独立且唯一的文件结构 , Linux 中每个分区都是用来组成整个文件系统的一部分。
Linux 采用了一种叫“载入” 的处理方法, 它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来。 这时要载入的一个分区将使它的存储空间在一个目录下获得。
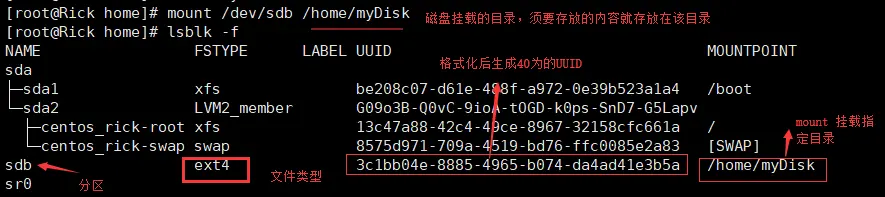
可以通过命令 lsblk -f 查看磁盘分区信息

- 磁盘分区案例
这里通过虚拟机来模拟添加一块磁盘,并操作分区,挂载到系统中使用。
- 添加一块硬盘
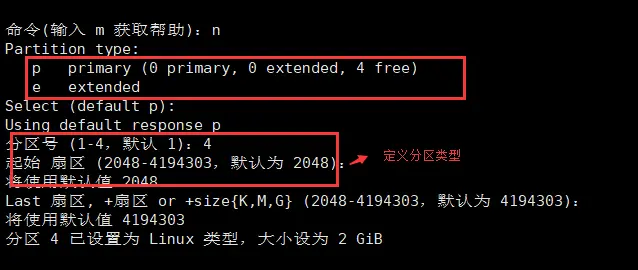
- 执行分区
fdisk /dev/sdb
fdisk 命令如:
m 显示命令列表
p 显示磁盘分区 同 fdisk – l
n 新增分区
d 删除分区
w 写入并退出
2
3
4
5
6
7
8
**说明: ** 开始分区后输入 n, 新增分区, 然后选择 p , 分区类型为主分区。 两次回车默认剩余全部空间。 最后输入 w 写入分区并退出, 若不保存退出输入 q
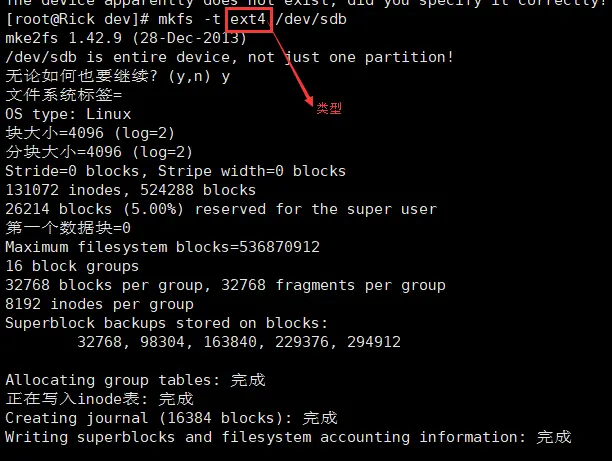
- 格式化磁盘(生成磁盘唯一标识)
mkfs -t ext4 /dev/sdb
- 挂载分区(为磁盘指定一个目录)
mount /dev/sdb /myDisk (挂载)
umount 设备名称或者挂载目录 如:umount /dev/sdb 或者 umount /myDisk
2
- 分区命令
- fdisk 分区命令
用于观察硬盘实体使用情况,也可对硬盘分区。它采用传统的问答式界面,而非类似DOS fdisk的cfdisk互动式操作界面,因此在使用上较为不便,但功能却丝毫不打折扣。
-b<分区大小>:指定每个分区的大小;
-l:列出指定的外围设备的分区表状况;
-s<分区编号>:将指定的分区大小输出到标准输出上,单位为区块;
-u:搭配"-l"参数列表,会用分区数目取代柱面数目,来表示每个分区的起始地址;
-v:显示版本信息。
2
3
4
5
- df 磁盘空间信息命令
用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
df 查看系统磁盘设备,默认是KB为单位
df -h 以kb为单位查看
df -a 查看所有
df --block-size=<区块大小>:以指定的区块大小来显示区块数目
df -k或--kilobytes:指定区块大小为1024字节
2
3
4
5
- du 磁盘使用情况命令
也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。
du [文件名] 查看文件所占用的空间
du -h /目录 查询指定目录的磁盘占用情况, 默认为当前目录
du -a或-all 显示目录中个别文件的大小。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
2
3
4
5
6
7
# 1.10. 网络设置
ping 链接远程主机,测试网络是否畅通
配置网络
# 打开网络配置文件
/etc/sysconfig/network-scripts/ifcfg-enp0s3
# 配置文件说明
# 类型
TYPE="Ethernet"
# 代理方法
PROXY_METHOD="none"
BROWSER_ONLY="no"
# ip配置方法[none|dhcp|static|bootp]--->(引导不适用协议|DHCP协议|静态分配协议|BOOTP协议)
BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp0s3"
# 随机id
UUID="8586cd8d-36d0-4daf-915e-3845bc0819c9"
# 接口名称(设备号)
DEVICE="enp0s3"
# 系统启动是网络接口是否生效(yes/no)
ONBOOT="yes"
# 配置好后重启服务
service network restart
# 重启计算机
reboot
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- 查看系统网络情况
netstat [选项]
netstat -anp (常用)
ifconfig 查看网络设备地址信息 就是ip信息
netstat -ap | grep ssh 找出程序运行的端口
netstat -an | grep ':80' 找出运行在指定端口的进程
2
3
4
# 1.11. 进程管理
在 LINUX 中, 每个执行的程序(代码) 都称为一个进程。 每一个进程都分配一个 ID 号。每一个进程, 都会对应一个父进程, 而这个父进程可以复制多个子进程。 例如 www 服务器。每个进程都可能以两种方式存在的, 前台与后台, 所谓前台进程就是用户目前的屏幕上可以进操作的。 后台进程则是实际在操作, 但由于屏幕上无法看到的进程, 通常使用后台方式执行。一般系统的服务都是以后台进程的方式存在, 而且都会常驻在系统中。 直到关机才才结束。
- ps 线程查看指令
# 查看线程
ps -aux (常用)
ps -ef(常用)
ps -ef | grep vim (通过grep 过滤查找)
# -a 显示所有终端机下执行的程序,除了阶段作业领导者之外
# -u 以用户为主的格式来显示程序状况
# -x 显示所有程序,不以终端机来区分
# e 列出程序时,显示每个程序所使用的环境变量。
2
3
4
5
6
7
8
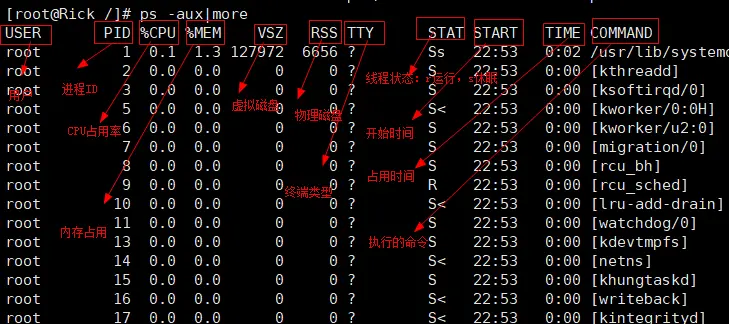
指令说明
- System V 展示风格
- USER: 用户名称
- PID: 进程号
- %CPU: 进程占用 CPU 的百分比
- %MEM: 进程占用物理内存的百分比
- VSZ: 进程占用的虚拟内存大小(单位: KB)
- RSS: 进程占用的物理内存大小(单位: KB)
- TT: 终端名称,缩写 .
- STAT: 进程状态, 其中 S-睡眠, s-表示该进程是会话的先导进程, N-表示进程拥有比普通优先
级更低的优先级, R-正在运行, D-短期等待, Z-僵死进程, T-被跟踪或者被停止等等 - STARTED: 进程的启动时间
- TIME: CPU 时间, 即进程使用 CPU 的总时间
- COMMAND: 启动进程所用的命令和参数, 如果过长会被截断显示
ps -ef 是以全格式显示当前所有的进程 -e 显示所有进程。 -f 全格式。
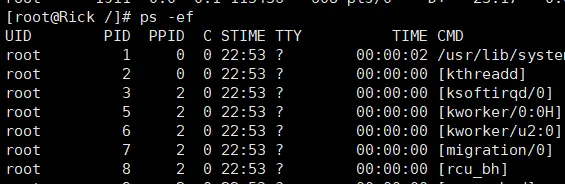
指令说明
- UID: 用户 ID
- PID: 进程 ID
- PPID: 父进程 ID
- C: CPU 用于计算执行优先级的因子。 数值越大, 表明进程是 CPU 密集型运算, 执行优先级会降低; 数值越小, 表明进程是 I/O 密集型运算, 执行优先级会提高
- STIME: 进程启动的时间
- TTY: 完整的终端名称
- TIME: CPU 时间
- CMD: 启动进程所用的命令和参数
- 终止进程
Linux中可以使用进程的名称来杀死进程(killall),使用此指令可以 杀死一组同名进程 。还可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall把这两个过程合二为一,是一个很好用的命令。
kill [选项] 进程号(功能描述: 通过进程号杀死进程)
-a:当处理当前进程时,不限制命令名和进程号的对应关系;
-l <信息编号:若不加<信息编号选项,则-l参数会列出全部的信息名称;
-p:指定kill 命令只打印相关进程的进程号,而不发送任何信号;
-s <信息名称或编号:指定要送出的信息;
-u:指定用户。
2
3
4
5
killall 进程名称 (功能描述: 通过进程名称杀死进程, 也支持通配符, 这在系统因负载过大而变得很慢时很有用)
-e:对长名称进行精确匹配;
-l:忽略大小写的不同;
-p:杀死进程所属的进程组;
-i:交互式杀死进程,杀死进程前需要进行确认;
-l:打印所有已知信号列表;
-q:如果没有进程被杀死。则不输出任何信息;
-r:使用正规表达式匹配要杀死的进程名称;
-s:用指定的进程号代替默认信号“SIGTERM”;
-u:杀死指定用户的进程
2
3
4
5
6
7
8
9
- 进程树
pstree 命令能够让进城以树状图的方式展现进程之间的派生关系,显示效果比较直观。
-a:显示每个程序的完整指令,包含路径,参数或是常驻服务的标示;
-c:不使用精简标示法;
-G:使用VT100终端机的列绘图字符;
-h:列出树状图时,特别标明现在执行的程序;
-H<程序识别码>:此参数的效果和指定"-h"参数类似,但特别标明指定的程序;
-l:采用长列格式显示树状图;
-n:用程序识别码排序。预设是以程序名称来排序;
-p:显示程序识别码;
-u:显示用户名称;
-U:使用UTF-8列绘图字符;
-V:显示版本信息。
ps -p 显示当前所有进程的进程号和进程id
pstree -a 显示所有进程的所有详细信息,遇到相同的进程名可以压缩显示。
2
3
4
5
6
7
8
9
10
11
12
13
14
- top 动态监控进程
top 与 ps 命令很相似。 它们都用来显示正在执行的进程。 Top 与 ps 最大的不同之处, 在于 top 在执行一段时间可以更新正在运行的的进程。
top[参数]
命令选项
-b:以批处理模式操作;
-c:显示完整的治命令;
-d:屏幕刷新间隔时间;
-I:忽略失效过程;
-s:保密模式;
-S:累积模式;
-i<时间:设置间隔时间;
-u<用户名:指定用户名;
-p<进程号:指定进程;
-n<次数:循环显示的次数。
2
3
4
5
6
7
8
9
10
实时监控线程切换参数
h:显示帮助画面,给出一些简短的命令总结说明;
k:终止一个进程;
i:忽略闲置和僵死进程,这是一个开关式命令;
q:退出程序;
r:重新安排一个进程的优先级别;
S:切换到累计模式;
s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;
f或者F:从当前显示中添加或者删除项目;
o或者O:改变显示项目的顺序;
l:切换显示平均负载和启动时间信息;
m:切换显示内存信息;
t:切换显示进程和CPU状态信息;
c:切换显示命令名称和完整命令行;
M:根据驻留内存大小进行排序;
P:根据CPU使用百分比大小进行排序;
T:根据时间/累计时间进行排序;
w:将当前设置写入~/.toprc文件中。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 实例参数说明
top - 09:22:19 up 12 min, 1 user, load average: 0.00, 0.04, 0.05
Tasks: 94 total, 2 running, 92 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 499420 total, 220756 free, 102140 used, 176524 buff/cache
KiB Swap: 839676 total, 839676 free, 0 used. 356936 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 127972 6608 4160 S 0.0 1.3 0:02.10 systemd
1025 root 20 0 432476 24048 13080 S 0.0 4.8 0:01.74 dockerd-current
684 root 20 0 358232 29172 7180 S 0.0 5.8 0:01.60 firewalld
1311 Rick 20 0 161976 2204 1548 R 0.7 0.4 0:01.34 top
#########################说明##################
top - 09:44:56[当前系统时间],
16 days[系统已经运行了16天],
1 user[个用户当前登录],
load average: 9.59, 4.75, 1.92[系统负载,即任务队列的平均长度]
Tasks: 145 total[总进程数],
2 running[正在运行的进程数],
143 sleeping[睡眠的进程数],
0 stopped[停止的进程数],
0 zombie[冻结进程数],
Cpu(s): 99.8%us[用户空间占用CPU百分比],
0.1%sy[内核空间占用CPU百分比],
0.0%ni[用户进程空间内改变过优先级的进程占用CPU百分比],
0.2%id[空闲CPU百分比], 0.0%wa[等待输入输出的CPU时间百分比],
0.0%hi[],
0.0%st[],
Mem: 4147888k total[物理内存总量],
2493092k used[使用的物理内存总量],
1654796k free[空闲内存总量],
158188k buffers[用作内核缓存的内存量]
Swap: 5144568k total[交换区总量],
56k used[使用的交换区总量],
5144512k free[空闲交换区总量],
2013180k cached[缓冲的交换区总量]
#########################说明##################
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 1.12. 服务管理
服务(service) 本质就是进程, 但是是运行在后台的, 通常都会监听某个端口, 等待其它程序的请求, 比如(mysql , sshd 防火墙等), 因此我们又称为守护进程, 是 Linux 中非常重要的知识点。
在 CentOS7.0 之前一般使用 service 命令来查看和管理服务;而之后使用 systemctl 命令,它比前者强大,集成了service 和 chkconfig命令。
- service 命令
service 服务名 start #启动服务
service 服务名 stop #停止服务
service 服务名 restart #重启服务
service 服务名 reload #重新载入服务配置
service 服务名 status #查看服务状态
service 服务名 --status-all #查看所有服务状态
2
3
4
5
6
- systemctl 命令
| 任务 | 旧指令 | 新指令 |
|---|---|---|
| 使某服务自动启动 | chkconfig --level 3 [httpd] on | systemctl [enable] httpd.service |
| 使某服务不自动启动 | chkconfig --level 3 httpd off | systemctl disable httpd.service |
| 检查服务状态 | service httpd status | systemctl status httpd.service (服务详细信息) systemctl is-active httpd.service (仅显示是否 Active) |
| 显示所有已启动的服务 | chkconfig --list | systemctl list-units --[type]=service |
| 启动某服务 | service httpd start | systemctl start httpd.service |
| 停止某服务 | service httpd stop | systemctl stop httpd.service |
| 重启某服务 | service httpd restart | systemctl restart httpd.service |
案例
# 启动nfs服务
systemctl start nfs-server.service
# 设置开机自启动
systemctl enable nfs-server.service
# 14. 停止开机自启动
systemctl disable nfs-server.service
# 查看服务当前状态
systemctl status nfs-server.service
# 重新启动某服务
systemctl restart nfs-server.service
# 查看所有已启动的服务
# 停止防火墙
systemctl stop firewalld.service
# 禁止防火墙开启启动
systemctl disable firewalld.service
2
3
4
5
6
7
8
9
10
11
12
13
14
15
systemctl以及Unit说明: https://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-commands.html https://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-part-two.html
- chkconfig 指令
通过 chkconfig 命令可以给每个服务的各个运行级别设置自启动/关闭
chkconfig /chkconfig --list # 查看服务 每一服务,在不同运行级别下的开启或关闭状况
chkconfig telnet off # 关闭 Telnet 服务
chkconfig telnet on //开启 Telnet 服务
2
3
开机启动流程
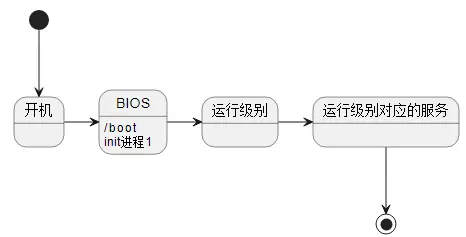
# 1.13. 防火墙
- firewall 命令
# 启动
systemctl start firewalld
# 查看状态
systemctl status firewalld 或者 firewall-cmd --state
# 停止
systemctl disable firewalld
# 禁用
systemctl stop firewalld
# 查看开放了那些端口
firewall-cmd --list-services
# 查看还有哪些服务可以打开
firewall-cmd --get-services
# 查看所有打开的端口
firewall-cmd --zone=public --list-ports
# 更新防火墙
firewall-cmd --reload
# 15. 添加一个服务到firewalld
firewall-cmd --add-service=http //http换成想要开放的service
# 开指定端口
firewall-cmd --zone=public --add-port=80/tcp --permanent
# 查看开发的端口
firewall-cmd --zone= public --query-port=80/tcp
# 删除开发的端口
firewall-cmd --zone= --remove-port=80/tcp --permanent
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- iptables 命令
iptables命令选项输入顺序
iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作
- 命令选项
-t<表>:指定要操纵的表;
-A:向规则链中添加条目;
-D:从规则链中删除条目;
-i:向规则链中插入条目;
-R:替换规则链中的条目;
-L:显示规则链中已有的条目;
-F:清楚规则链中已有的条目;
-Z:清空规则链中的数据包计算器和字节计数器;
-N:创建新的用户自定义规则链;
-P:定义规则链中的默认目标;
-h:显示帮助信息;
-p:指定要匹配的数据包协议类型;
-s:指定要匹配的数据包源ip地址;
-j<目标>:指定要跳转的目标;
-i<网络接口>:指定数据包进入本机的网络接口;
-o<网络接口>:指定数据包要离开本机所使用的网络接口。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
四大表 raw:高级功能,如:网址过滤。
mangle:数据包修改(QOS),用于实现服务质量。
net:地址转换,用于网关路由器。
filter:包过滤,用于防火墙规则。五大规则
INPUT链:处理输入数据包。
OUTPUT链:处理输出数据包。
PORWARD链:处理转发数据包。
PREROUTING链:用于目标地址转换(DNAT)。
POSTOUTING链:用于源地址转换(SNAT)。
- 七大动作
ACCEPT:接收数据包。
DROP:丢弃数据包。
REDIRECT:重定向、映射、透明代理。
SNAT:源地址转换。
DNAT:目标地址转换。
MASQUERADE:IP伪装(NAT),用于ADSL。
LOG:日志记录。
- 常用组合命令
# 查看已有规则
iptables -L -n -v
# 清除规则
iptables -F #清楚规则链中已有的条目
iptables -X #清空规则链中的数据包计算器和字节计数器
iptables -Z
#开放指定端口
iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT #允许本地回环接口(即运行本机访问本机)
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT #允许已建立的或相关连的通行
iptables -A OUTPUT -j ACCEPT #允许所有本机向外的访问
iptables -A INPUT -p tcp --dport 22 -j ACCEPT #允许访问22端口
iptables -A INPUT -p tcp --dport 80 -j ACCEPT #允许访问80端口
iptables -A INPUT -p tcp --dport 21 -j ACCEPT #允许ftp服务的21端口
iptables -A INPUT -p tcp --dport 20 -j ACCEPT #允许FTP服务的20端口
iptables -A INPUT -j reject #禁止其他未允许的规则访问
iptables -A FORWARD -j REJECT #禁止其他未允许的规则访问
#屏蔽IP
iptables -I INPUT -s 123.45.6.7 -j DROP #屏蔽单个IP的命令
iptables -I INPUT -s 123.0.0.0/8 -j DROP #封整个段即从123.0.0.1到123.255.255.254的命令
iptables -I INPUT -s 124.45.0.0/16 -j DROP #封IP段即从123.45.0.1到123.45.255.254的命令
iptables -I INPUT -s 123.45.6.0/24 -j DROP #封IP段即从123.45.6.1到123.45.6.254的命令是
#删除
iptables -L -n --line-numbers
iptables -D INPUT 8 删除已添加的iptables规则
iptables -D INPUT -s 192.168.1.5 -j DROP #删除黑名单192.168.1.5
# 有时候要删除的规则太长,删除时要写一大串,既浪费时间又容易写错,这时我们可以先使用–line-number找出该条规则的行号,再通过行号删除规则。如上
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 1.14. 软件包管理
一种用于互联网下载包的打包及安装工具, 它包含在某些 Linux 分发版中。 它生成具有.RPM扩展名的文件。 RPM 是 RedHat Package Manager(RedHat 软件包管理工具) 的缩写, 类似 windows 的 setup.exe, 这一文件格式名称虽然打上了 RedHat 的标志, 但理念是通用的。Linux 的分发版本都有采用(suse,redhat, centos 等等) , 可以算是公认的行业标准了。
- RPM 包管理命令
- 命令选项
-a:查询所有套件;
-b<完成阶段<套件档+或-t <完成阶段<套件档+:设置包装套件的完成阶段,并指定套件档的文件名称;
-c:只列出组态配置文件,本参数需配合"-l"参数使用;
-d:只列出文本文件,本参数需配合"-l"参数使用;
-e<套件档或--erase<套件档:删除指定的套件;
-f<文件+:查询拥有指定文件的套件;
-h或--hash:套件安装时列出标记;
-i<套件档或--install<套件档:安装指定的套件档;
-l:显示套件的文件列表;
-p<套件档+:查询指定的RPM套件档;
-q:使用询问模式,当遇到任何问题时,rpm指令会先询问用户;
-R:显示套件的关联性信息;
-s:显示文件状态,本参数需配合"-l"参数使用;
-U<套件档或--upgrade<套件档:升级指定的套件档;
-v:显示指令执行过程;
-vv:详细显示指令执行过程,便于排错。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 常用指令
rpm -qa :查询所安装的所有 rpm 软件包
rpm -qa|grep '程序名称' 查询指定程序是否安装
rpm -q 软件包名 :查询软件包是否安装 rpm -q firefox
rpm -qi 软件包名 : 查询软件包信息
rpm -ql 软件包名 :查询软件包中的文件**(查看程序安装到了那个目录)**
rpm -qf 文件全路径名 查询文件所属的软件包 **(查看那个路径是那个程序的)**
rpm -e RPM 包的名称
rpm -e --nodes rpm包名称 强制删除
rpm -ivh 包名 安装rpm软件包
2
3
4
5
6
7
8
9
- Yum 包管理命令
Yum 是一个 Shell 前端软件包管理器。 基于 RPM 包管理, 能够从指定的服务器自动下载 RPM包并且安装, 可以自动处理依赖性关系, 并且一次安装所有依赖的软件包
1. 安装
yum install #全部安装
yum install package1 #安装指定的安装包package1
yum groupinsall group1 #安装程序组group1
rpm -ivh # 安装
# 2. 更新
yum update #全部更新
yum update package1 #更新指定程序包package1
yum check-update #检查可更新的程序
yum upgrade package1 #升级指定程序包package1
yum groupupdate group1 #升级程序组group1
# 3. 查找和显示
yum info package1 #显示安装包信息package1
yum list #显示所有已经安装和可以安装的程序包
yum list package1 #显示指定程序包安装情况package1
yum groupinfo group1 #显示程序组group1信息
yum search string 根据关键字string查找安装包
# 4. 删除
yum remove package1 #删除程序包package1
yum groupremove group1 #删除程序组group1
yum deplist package1 #查看程序package1依赖情况
# 2. 清除缓存
yum clean packages #清除缓存目录下的软件包
yum clean headers #清除缓存目录下的 headers
yum clean oldheaders #清除缓存目录下旧的 headers
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 2. Shell
Linux 运维工程师在进行服务器集群管理时, 需要编写 Shell 程序来进行服务器管理。 对于 JavaEE 和 Python 程序员来说,工作的需要,你的老大会要求你编写一些 Shell 脚本进行程 序或者是服务器的维护, 比如编写一个定时备份数据库的脚本。 对于大数据程序员来说, 需要编写 Shell 程序来管理集群。
Shell 是一个命令行解释器, 它为用户提供了一个向 Linux 内核发送请求以便运行程序的界面系统级程序, 用户可以用 Shell 来启动、 挂起、 停止甚至是编写一些程序.
# 2.1. 基础语法
- 文件头
编写sh命令须要有文件头 #!/bin/bash
- 执行脚本
需要有脚本执行权限 当前路径执行:./a.sh 绝对路径执行:/home/a.sh sh+脚本(不建议使用)
- 变量
linux 系统分为本地变量和系统变量 本地变量: 系统变量: 定义静态变量:readonly 如:readonly A=121 变量定义 varname=value
命名规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
- 字符串定义
单引号或者双引号,当多个命令执行赋值给指定的变量是使用反引号``
# 字符串有关操作
# 字符串拼接
your_name="qinjx"
greeting="hello, "$your_name" !"
greeting_1="hello, ${your_name} !"
echo $greeting $greeting_1
# 获取字符串长度
string="abcd"
echo ${#string} #输出 4
# 截取字符串
string="runoob is a great site"
echo ${string:1:4} # 输出 unoo
# 操作字符串的位置
string="runoob is a great company"
echo `expr index "$string" is` # 输出 8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 数组
# 数组定义
array_name=(value0 value1 value2 value3)
# 指定索引定义数组
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen
# 获取
${数组名[下标]}
valuen=${array_name[n]} n=@时可以获取所有的元素
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 环境变量设置
export 变量名=变量值 (功能描述: 将 shell 变量输出为环境变量) source 配置文件 (功能描述: 让修改后的配置信息立即生效) echo $变量名 (功能描述: 查询环境变量的值)
- 位置变量参数
当我们执行一个 shell 脚本时, 如果希望获取到命令行的参数信息, 就可以使用到位置参数变 量, 比如 : ./myshell.sh 100 200 , 这个就是一个执行 shell 的命令行, 可以在 myshell 脚本中获取到参数信息
$n 功能描述: n 为数字, $0 代表命令本身, $1-$9 代表第一到第九个参数, 十以上的参数, 十以上的参数需要用大括号包含, 如${10}
$* 功能描述: 这个变量代表命令行中所有的参数, $*把所有的参数看成一个整体
$@ 功能描述: 这个变量也代表命令行中所有的参数, 不过$@把每个参数区分对待
$# 功能描述: 这个变量代表命令行中所有参数的个数
2
3
4
- 预定义变量
就是 shell 设计者事先已经定义好的变量, 可以直接在 shell 脚本中使用
$$ 功能描述: 当前进程的进程号(PID)
$! 功能描述: 后台运行的最后一个进程的进程号(PID)
$? 功能描述: 最后一次执行的命令的返回状态。 如果这个变量的值为 0, 证明上一个命令正确执行;
如果这个变量的值为非 0(具体是哪个数, 由命令自己来决定) , 则证明上一个命令执行不正确了。
2
3
4
- 运算符
“$((运算式))” 或“$[运算式]”
expr m + n
注意 expr 运算符间要有空格
expr m - n
expr \*, /, % 乘, 除, 取余
2
3
4
5
#!/bin/bash
echo "当前运行的进程号=$$"
# 运行的进程
./lee.sh 1 2 3
echo "最后执行的进程号=$!"
echo "是否执行成功=$?"
echo `expr 2 + 3`
2
3
4
5
6
7
- 流程控制
- 两个整数的比较
= 字符串比较
-lt 小于
-le 小于等于
-eq 等于
-gt 大于
-ge 大于等于
-ne 不等于
2
3
4
5
6
7
- 按照文件权限进行判断
-r 有读的权限 [ -r 文件 ]
-w 有写的权限
-x 有执行的权限
2
3
- 按照文件类型进行判断
-f 文件存在并且是一个常规的文件
-e 文件存在
-d 文件存在并是一个目录
2
3
- if语句
if [ 条件判断式 ];then
程序
fi
或者
if [ 条件判断式 ]
then
程序
elif [条件判断式]
then
程序
fi
2
3
4
5
6
7
8
9
10
11
12
# 2.2. 案例
- if 条件语句
#!/bin/bash
if [ $1 -eq 60 ]
then
echo "及格"
elif [ $1 -lt 60 ]
then
echo "不及格"
elif [ $1 -ge 80 && -lt "90" ]
then
echo "优秀"
fi
2
3
4
5
6
7
8
9
10
11
12
- case 语句
case $变量名 in
"值 1")
如果变量的值等于值 1, 则执行程序 1
;;
"值 2")
如果变量的值等于值 2, 则执行程序 2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值, 则执行此程序
;;
esac
2
3
4
5
6
7
8
9
10
11
12
#!/bin/bash
case $1 in
"1") echo "哈哈" ;;
"2") echo "哈哈2" ;;
"3") echo "哈哈3" ;;
"4") echo "哈哈4"
esac
2
3
4
5
6
7
- for循环
for 变量 in 值 1 值 2 值 3…
do
程序
done
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
2
3
4
5
6
7
8
9
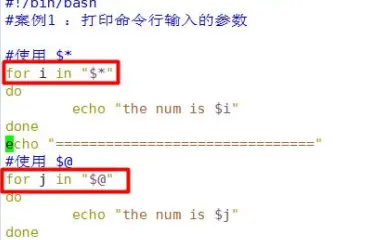

- while 语句
while [ 条件判断式 ]
do
程序
done
2
3
4

- 读取控制台参数
# read(选项)(参数)
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒) , 如果没有在指定的时间内输入, 就不再等待了
2
3
#!/bin/bash
#read -p "请输入参数:" a
read -t 5 -p "请输入参数:" a
echo "$a"
2
3
4
# 3. 其他问题
- centos7.0 没有netstat 和 ifconfig命令问题
通过yum search 这个命令我们发现ifconfig这个命令是在net-tools.x86_64这个包里, 运行 yum install net-tools 安装即可
- linux 没有pstree 命令
通过yum 安装工具支持即可:yum install psmisc
- 脚本后台执行命令
# 日志输出到/dev/null,也就是启动日志输出丢弃掉
shell命令 > /dev/null 2>&1
nohup [命令] > nohup.log 2>&1 执行输出到nohup文件,默认nohup文件是nohup.out
2
3
4
对于&1更准确的说应该是文件描述符1,而1标识标准输出stdout。
对于2表示标准错误stderr。
2>&1 的意思就是将标准错误重定向到标准输出。这里标准输出已经重定向到了 /dev/null。那么标准错误也会输出到 /dev/null
警告
/dev/null 可以看作"黑洞",它等价于一个只写文件, 所有写入它的内容都会永远丢失;而尝试从它那儿读取内容则什么也读不到。
在生产环境,切忌不可以这么使用,日志丢掉后,没办法追述问题。